 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCircular Rectifiction of 3D Video and Efficient Modification of 3D-HEVC
Jun 09, 2023Video acquired from multiple cameras located along a line is often rectified to video virtually obtained from cameras with ideally parallel optical axes collocated on a single plane and principal points on a line. Such an approach simplifies video processing including depth estimation and compression. Nowadays, for many application video, like virtual reality or virtual navigation, the content is often acquired by cameras located nearly on a circle or on a part of that. Therefore, we introduce new operation of circular rectification that results in multiview video virtually obtained from cameras located on an ideal arc and with optical axes that are collocated on a single plane and they intersect in a single point. For the circularly rectified video, depth estimation and compression are simplified. The standard 3DHEVC codec was designed for rectified video and its efficiency is limited for video acquired from cameras located on an arc. Therefore, we developed a 3-D HEVC codec modified in order to compress efficiently circularly rectified video. The experiments demonstrate its better performance than for the standard 3D-HEVC codec.
Video Coding for Machines: Partial transmission of SIFT features
Jan 07, 2022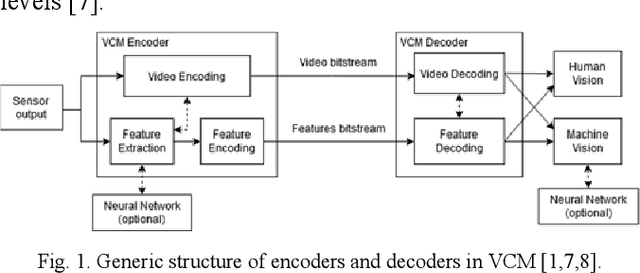

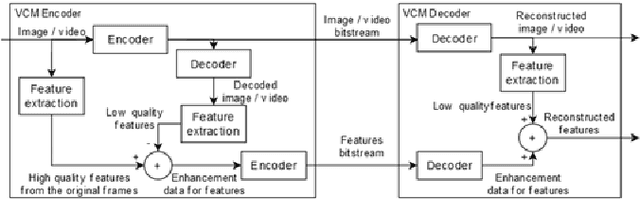

The paper deals with Video Coding for Machines that is a new paradigm in video coding related to consumption of decoded video by humans and machines. For such tasks, joint transmission of compressed video and features is considered. In this paper, we focus our considerations of features on SIFT keypoints. They can be extracted from the decoded video with losses in number of keypoints and their parameters as compared to the SIFT keypoints extracted from the original video. Such losses are studied for HEVC and VVC as functions of the quantization parameter and the bitrate. In the paper, we propose to transmit the residual feature data together with the compressed video. Therefore, even for strongly compressed video, the transmission of whole all SIFT keypoint information is avoided.
Multiview Video Compression Using Advanced HEVC Screen Content Coding
Jun 25, 2021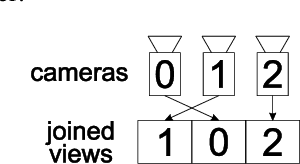
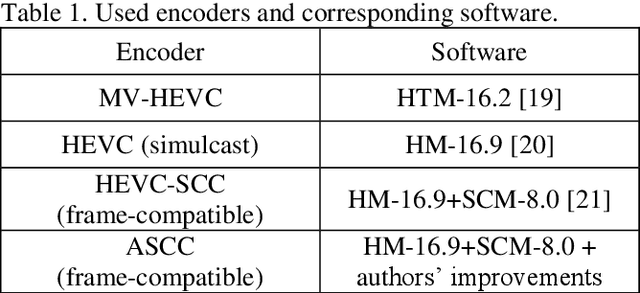


The paper presents a new approach to multiview video coding using Screen Content Coding. It is assumed that for a time instant the frames corresponding to all views are packed into a single frame, i.e. the frame-compatible approach to multiview coding is applied. For such coding scenario, the paper demonstrates that Screen Content Coding can be efficiently used for multiview video coding. Two approaches are considered: the first using standard HEVC Screen Content Coding, and the second using Advanced Screen Content Coding. The latter is the original proposal of the authors that exploits quarter-pel motion vectors and other nonstandard extensions of HEVC Screen Content Coding. The experimental results demonstrate that multiview video coding even using standard HEVC Screen Content Coding is much more efficient than simulcast HEVC coding. The proposed Advanced Screen Content Coding provides virtually the same coding efficiency as MV-HEVC, which is the state-of-the-art multiview video compression technique. The authors suggest that Advanced Screen Content Coding can be efficiently used within the new Versatile Video Coding (VVC) technology. Nevertheless a reference multiview extension of VVC does not exist yet, therefore, for VVC-based coding, the experimental comparisons are left for future work.
Depth Map Estimation for Free-Viewpoint Television
Sep 05, 2019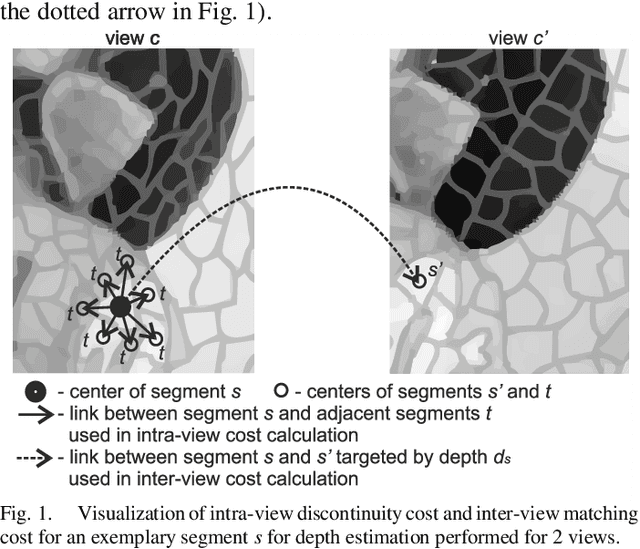
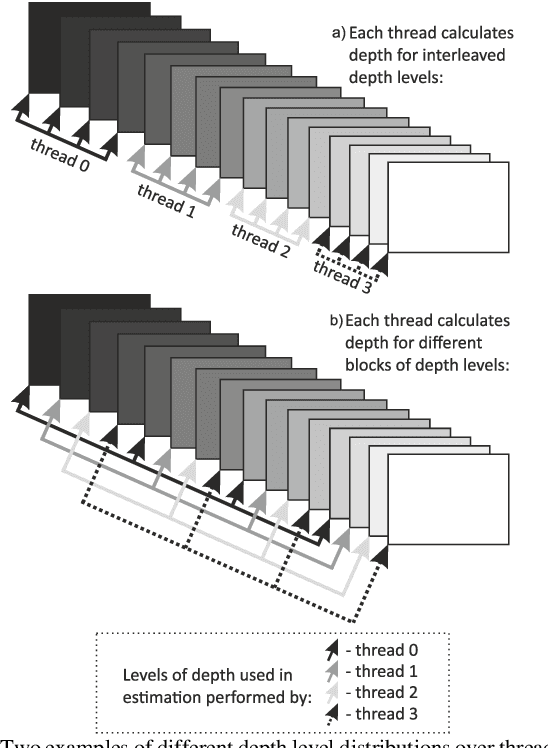
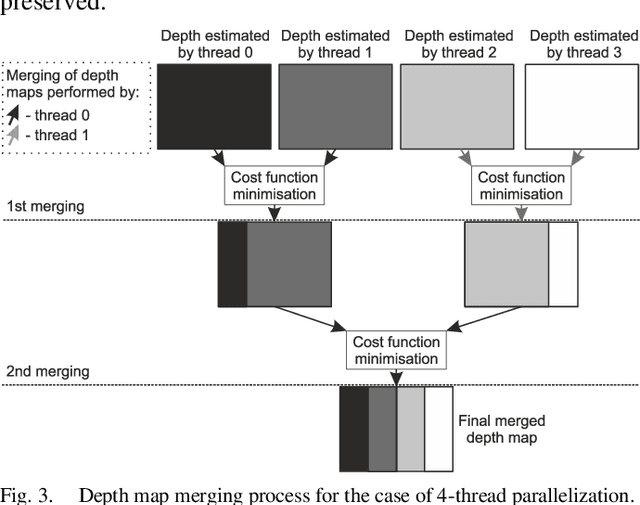

The paper presents a new method of depth estimation dedicated for free-viewpoint television (FTV). The estimation is performed for segments and thus their size can be used to control a trade-off between the quality of depth maps and the processing time of their estimation. The proposed algorithm can take as its input multiple arbitrarily positioned views which are simultaneously used to produce multiple inter view consistent output depth maps. The presented depth estimation method uses novel parallelization and temporal consistency enhancement methods that significantly reduce the processing time of depth estimation. An experimental assessment of the proposals has been performed, based on the analysis of virtual view quality in FTV. The results show that the proposed method provides an improvement of the depth map quality over the state of-the-art method, simultaneously reducing the complexity of depth estimation. The consistency of depth maps, which is crucial for the quality of the synthesized video and thus the quality of experience of navigating through a 3D scene, is also vastly improved.