 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehavioural Reports of Multi-Stage Malware
Jan 30, 2023



The extensive damage caused by malware requires anti-malware systems to be constantly improved to prevent new threats. The current trend in malware detection is to employ machine learning models to aid in the classification process. We propose a new dataset with the objective of improving current anti-malware systems. The focus of this dataset is to improve host based intrusion detection systems by providing API call sequences for thousands of malware samples executed in Windows 10 virtual machines. A tutorial on how to create and expand this dataset is provided along with a benchmark demonstrating how to use this dataset to classify malware. The data contains long sequences of API calls for each sample, and in order to create models that can be deployed in resource constrained devices, three feature selection methods were tested. The principal innovation, however, lies in the multi-label classification system in which one sequence of APIs can be tagged with multiple labels describing its malicious behaviours.
The effects of regularisation on RNN models for time series forecasting: Covid-19 as an example
May 09, 2021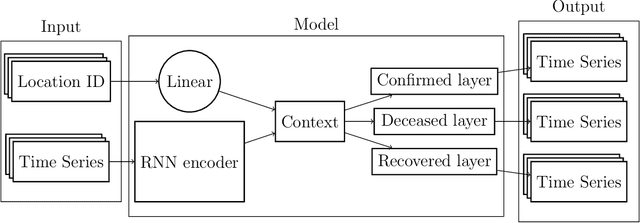
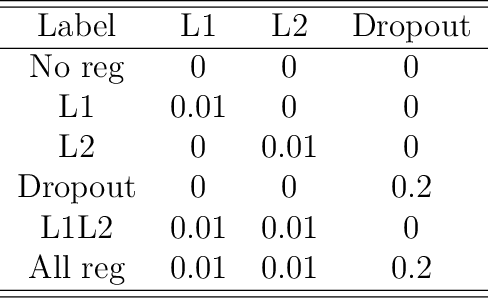
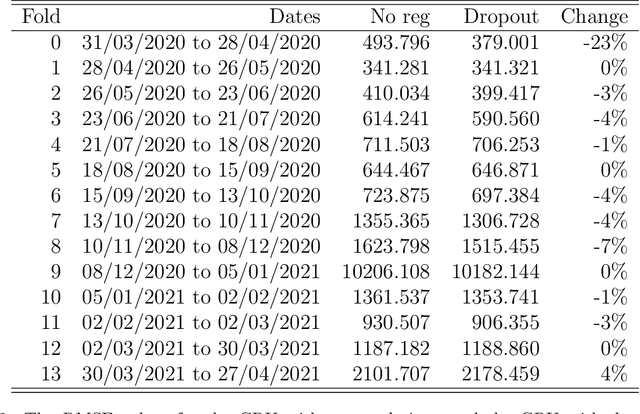
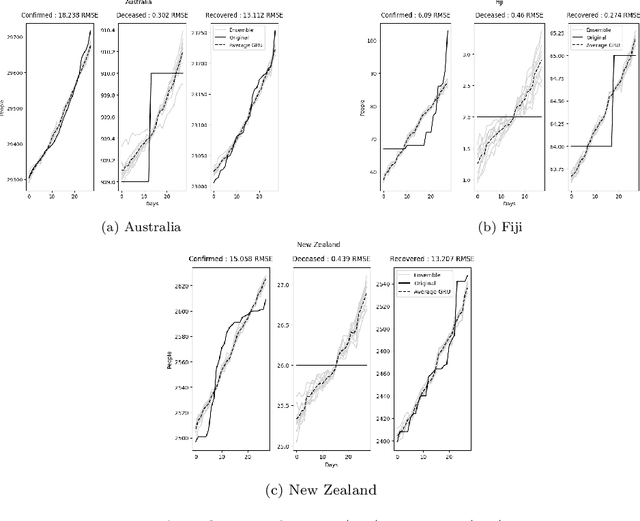
Many research papers that propose models to predict the course of the COVID-19 pandemic either use handcrafted statistical models or large neural networks. Even though large neural networks are more powerful than simpler statistical models, they are especially hard to train on small datasets. This paper not only presents a model with grater flexibility than the other proposed neural networks, but also presents a model that is effective on smaller datasets. To improve performance on small data, six regularisation methods were tested. The results show that the GRU combined with 20% Dropout achieved the lowest RMSE scores. The main finding was that models with less access to data relied more on the regulariser. Applying Dropout to a GRU model trained on only 28 days of data reduced the RMSE by 23%.