 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Neural Networks Implementation Proposal for Microcontrollers
Jun 08, 2020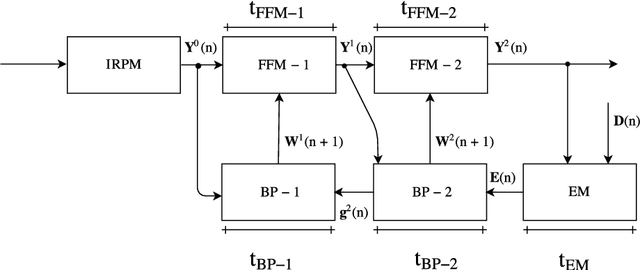
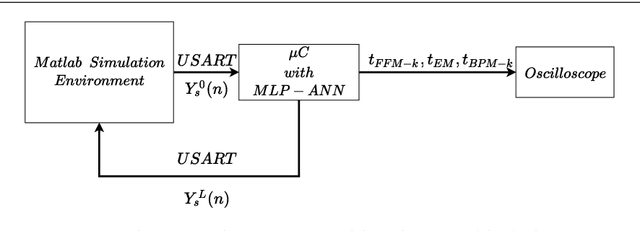
The adoption of intelligent systems with Artificial Neural Networks (ANNs) embedded in hardware for real-time applications currently faces a growing demand in fields like the Internet of Things (IoT) and Machine to Machine (M2M). However, the application of ANNs in this type of system poses a significant challenge due to the high computational power required to process its basic operations. This paper aims to show an implementation strategy of a Multilayer Perceptron (MLP) type neural network, in a microcontroller (a low-cost, low-power platform). A modular matrix-based MLP with the full classification process was implemented, and also the backpropagation training in the microcontroller. The testing and validation were performed through Hardware in the Loop (HIL) of the Mean Squared Error (MSE) of the training process, classification result, and the processing time of each implementation module. The results revealed a linear relationship between the values of the hyperparameters and the processing time required for classification, also the processing time concurs with the required time for many applications on the fields mentioned above. These findings show that this implementation strategy and this platform can be applied successfully on real-time applications that require the capabilities of ANNs.
Proposal of a Takagi-Sugeno Fuzzy-PI Controller Hardware
Mar 12, 2020This work proposes dedicated hardware for an intelligent control system on Field Programmable Gate Array (FPGA). The intelligent system is represented as Takagi-Sugeno Fuzzy-PI controller. The implementation uses a fully parallel strategy associated with a hybrid bit format scheme (fixed-point and other floating-point). Two hardware designs are proposed; the first one uses a single clock cycle processing architecture, and the other uses a pipeline scheme. The bit accuracy was tested by simulation with a non linear control system of a robotic manipulator. The area, throughput, and dynamic power consumption of the implemented hardware are used to validate and compare the results of this proposal. The results achieved allow that the proposal hardware can use in several applications with high-throughput, low-power and ultra-low-latency restrictions such as teleportation of robot manipulators, tactile internet, industrial automation in industry 4.0, and others.
Hardware Architecture Proposal for TEDA algorithm to Data Streaming Anomaly Detection
Mar 08, 2020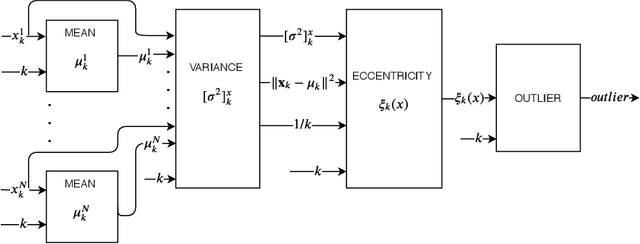

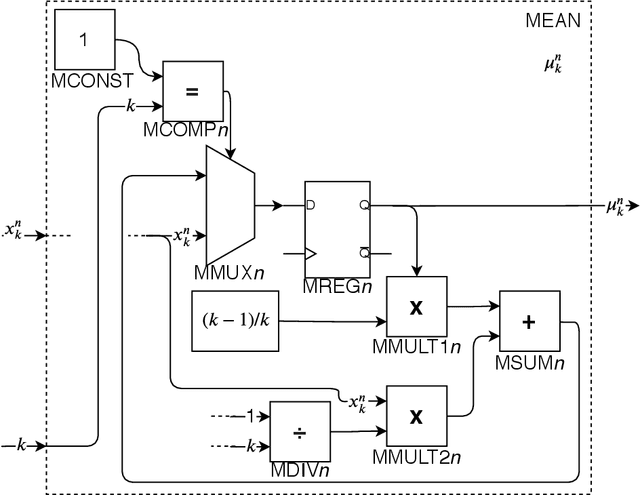
The amount of data in real-time, such as time series and streaming data, available today continues to grow. Being able to analyze this data the moment it arrives can bring an immense added value. However, it also requires a lot of computational effort and new acceleration techniques. As a possible solution to this problem, this paper proposes a hardware architecture for Typicality and Eccentricity Data Analytic (TEDA) algorithm implemented on Field Programmable Gate Arrays (FPGA) for use in data streaming anomaly detection. TEDA is based on a new approach to outlier detection in the data stream context. In order to validate the proposals, results of the occupation and throughput of the proposed hardware are presented. Besides, the bit accurate simulation results are also presented. The project aims to Xilinx Virtex-6 xc6vlx240t-1ff1156 as the target FPGA.
High-Performance Parallel Implementation of Genetic Algorithm on FPGA
Jun 20, 2018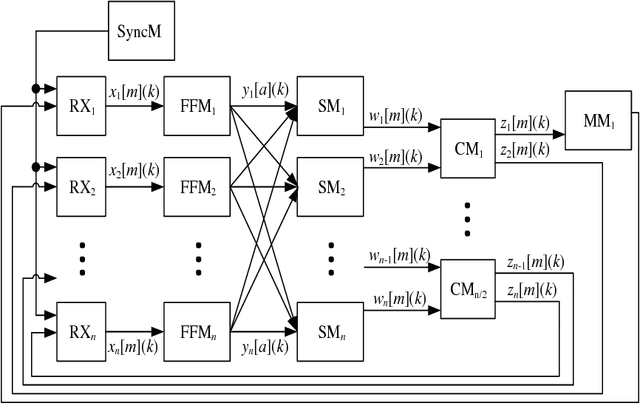
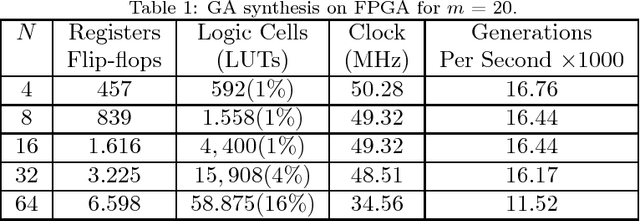
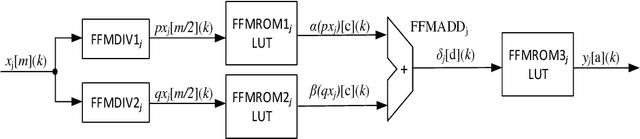
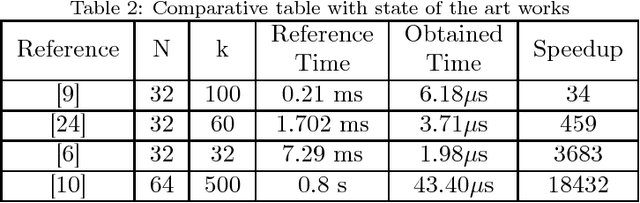
Genetic Algorithms (GAs) are used to solve search and optimization problems in which an optimal solution can be found using an iterative process with probabilistic and non-deterministic transitions. However, depending on the problem's nature, the time required to find a solution can be high in sequential machines due to the computational complexity of genetic algorithms. This work proposes a parallel implementation of a genetic algorithm on field-programmable gate array (FPGA). Optimization of the system's processing time is the main goal of this project. Results associated with the processing time and area occupancy (on FPGA) for various population sizes are analyzed. Studies concerning the accuracy of the GA response for the optimization of two variables functions were also evaluated for the hardware implementation. However, the high-performance implementation proposes in this paper is able to work with more variable from some adjustments on hardware architecture.