 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised speech unit discovery from articulatory and acoustic features using VQ-VAE
Jun 17, 2022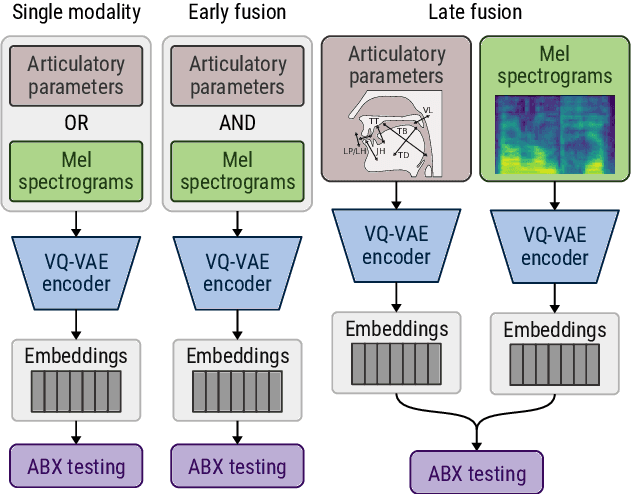
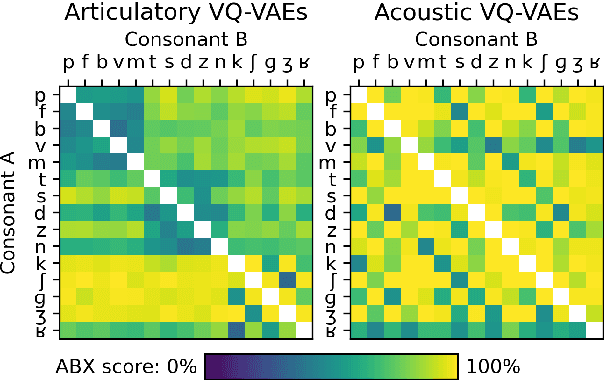
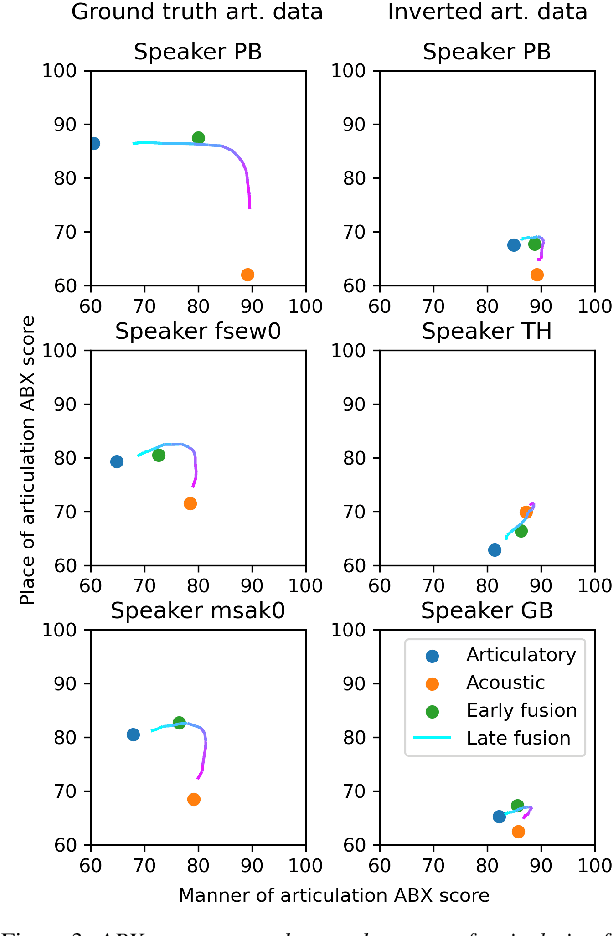
The human perception system is often assumed to recruit motor knowledge when processing auditory speech inputs. Using articulatory modeling and deep learning, this study examines how this articulatory information can be used for discovering speech units in a self-supervised setting. We used vector-quantized variational autoencoders (VQ-VAE) to learn discrete representations from articulatory and acoustic speech data. In line with the zero-resource paradigm, an ABX test was then used to investigate how the extracted representations encode phonetically relevant properties. Experiments were conducted on three different corpora in English and French. We found that articulatory information rather organises the latent representations in terms of place of articulation whereas the speech acoustics mainly structure the latent space in terms of manner of articulation. We show that an optimal fusion of the two modalities can lead to a joint representation of these phonetic dimensions more accurate than each modality considered individually. Since articulatory information is usually not available in a practical situation, we finally investigate the benefit it provides when inferred from the speech acoustics in a self-supervised manner.
Repeat after me: Self-supervised learning of acoustic-to-articulatory mapping by vocal imitation
Apr 05, 2022



We propose a computational model of speech production combining a pre-trained neural articulatory synthesizer able to reproduce complex speech stimuli from a limited set of interpretable articulatory parameters, a DNN-based internal forward model predicting the sensory consequences of articulatory commands, and an internal inverse model based on a recurrent neural network recovering articulatory commands from the acoustic speech input. Both forward and inverse models are jointly trained in a self-supervised way from raw acoustic-only speech data from different speakers. The imitation simulations are evaluated objectively and subjectively and display quite encouraging performances.
Learning robust speech representation with an articulatory-regularized variational autoencoder
Apr 07, 2021

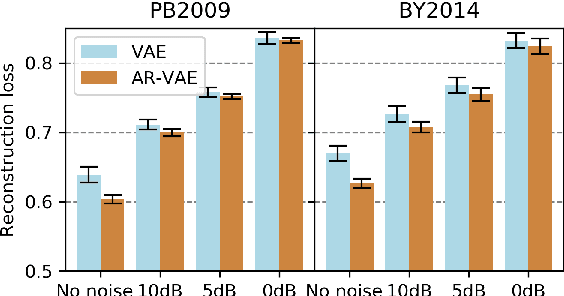

It is increasingly considered that human speech perception and production both rely on articulatory representations. In this paper, we investigate whether this type of representation could improve the performances of a deep generative model (here a variational autoencoder) trained to encode and decode acoustic speech features. First we develop an articulatory model able to associate articulatory parameters describing the jaw, tongue, lips and velum configurations with vocal tract shapes and spectral features. Then we incorporate these articulatory parameters into a variational autoencoder applied on spectral features by using a regularization technique that constraints part of the latent space to follow articulatory trajectories. We show that this articulatory constraint improves model training by decreasing time to convergence and reconstruction loss at convergence, and yields better performance in a speech denoising task.