 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecasting COVID-19 spreading trough an ensemble of classical and machine learning models: Spain's case study
Jul 12, 2022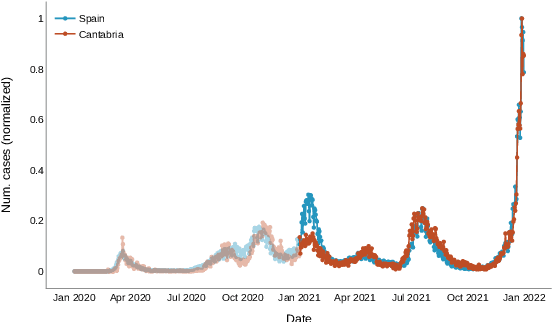

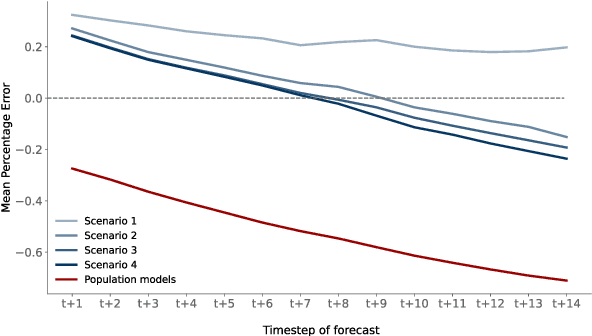
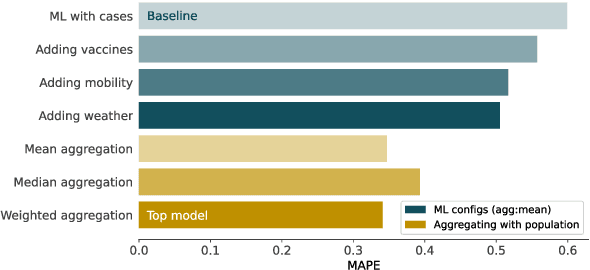
In this work we evaluate the applicability of an ensemble of population models and machine learning models to predict the near future evolution of the COVID-19 pandemic, with a particular use case in Spain. We rely solely in open and public datasets, fusing incidence, vaccination, human mobility and weather data to feed our machine learning models (Random Forest, Gradient Boosting, k-Nearest Neighbours and Kernel Ridge Regression). We use the incidence data to adjust classic population models (Gompertz, Logistic, Richards, Bertalanffy) in order to be able to better capture the trend of the data. We then ensemble these two families of models in order to obtain a more robust and accurate prediction. Furthermore, we have observed an improvement in the predictions obtained with machine learning models as we add new features (vaccines, mobility, climatic conditions), analyzing the importance of each of them using Shapley Additive Explanation values. As in any other modelling work, data and predictions quality have several limitations and therefore they must be seen from a critical standpoint, as we discuss in the text. Our work concludes that the ensemble use of these models improves the individual predictions (using only machine learning models or only population models) and can be applied, with caution, in cases when compartmental models cannot be utilized due to the lack of relevant data.