 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataAgent: Evaluating Large Language Models' Ability to Answer Zero-Shot, Natural Language Queries
Mar 29, 2024Conventional processes for analyzing datasets and extracting meaningful information are often time-consuming and laborious. Previous work has identified manual, repetitive coding and data collection as major obstacles that hinder data scientists from undertaking more nuanced labor and high-level projects. To combat this, we evaluated OpenAI's GPT-3.5 as a "Language Data Scientist" (LDS) that can extrapolate key findings, including correlations and basic information, from a given dataset. The model was tested on a diverse set of benchmark datasets to evaluate its performance across multiple standards, including data science code-generation based tasks involving libraries such as NumPy, Pandas, Scikit-Learn, and TensorFlow, and was broadly successful in correctly answering a given data science query related to the benchmark dataset. The LDS used various novel prompt engineering techniques to effectively answer a given question, including Chain-of-Thought reinforcement and SayCan prompt engineering. Our findings demonstrate great potential for leveraging Large Language Models for low-level, zero-shot data analysis.
Bidirectional Encoder Representations from Transformers (BERT): A sentiment analysis odyssey
Jul 02, 2020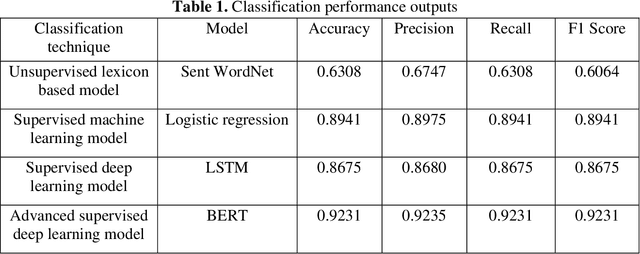
The purpose of the study is to investigate the relative effectiveness of four different sentiment analysis techniques: (1) unsupervised lexicon-based model using Sent WordNet; (2) traditional supervised machine learning model using logistic regression; (3) supervised deep learning model using Long Short-Term Memory (LSTM); and, (4) advanced supervised deep learning models using Bidirectional Encoder Representations from Transformers (BERT). We use publicly available labeled corpora of 50,000 movie reviews originally posted on internet movie database (IMDB) for analysis using Sent WordNet lexicon, logistic regression, LSTM, and BERT. The first three models were run on CPU based system whereas BERT was run on GPU based system. The sentiment classification performance was evaluated based on accuracy, precision, recall, and F1 score. The study puts forth two key insights: (1) relative efficacy of four highly advanced and widely used sentiment analysis techniques; (2) undisputed superiority of pre-trained advanced supervised deep learning BERT model in sentiment analysis from text data. This study provides professionals in analytics industry and academicians working on text analysis key insight regarding comparative classification performance evaluation of key sentiment analysis techniques, including the recently developed BERT. This is the first research endeavor to compare the advanced pre-trained supervised deep learning model of BERT vis-\`a-vis other sentiment analysis models of LSTM, logistic regression, and Sent WordNet.