 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Improved Document-level Embedding (HIDE)
Jun 01, 2020In recent times, word embeddings are taking a significant role in sentiment analysis. As the generation of word embeddings needs huge corpora, many applications use pretrained embeddings. In spite of the success, word embeddings suffers from certain drawbacks such as it does not capture sentiment information of a word, contextual information in terms of parts of speech tags and domain-specific information. In this work we propose HIDE a Hybrid Improved Document level Embedding which incorporates domain information, parts of speech information and sentiment information into existing word embeddings such as GloVe and Word2Vec. It combine improved word embeddings into document level embeddings. Further, Latent Semantic Analysis (LSA) has been used to represent documents as a vectors. HIDE is generated, combining LSA and document level embeddings, which is computed from improved word embeddings. We test HIDE with six different datasets and shown considerable improvement over the accuracy of existing pretrained word vectors such as GloVe and Word2Vec. We further compare our work with two existing document level sentiment analysis approaches. HIDE performs better than existing systems.
A Novel Framework based on SVDD to Classify Water Saturation from Seismic Attributes
Dec 02, 2016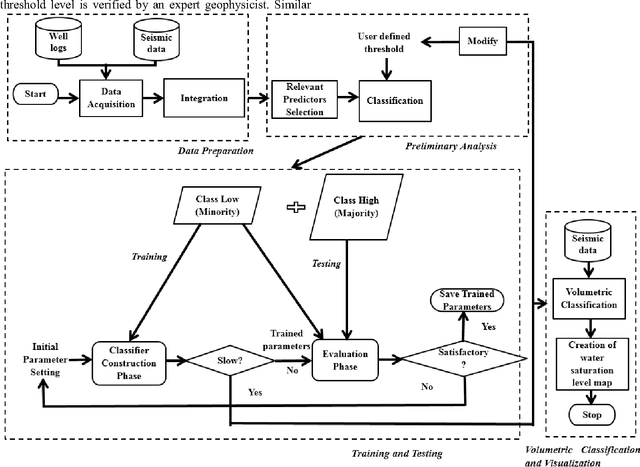
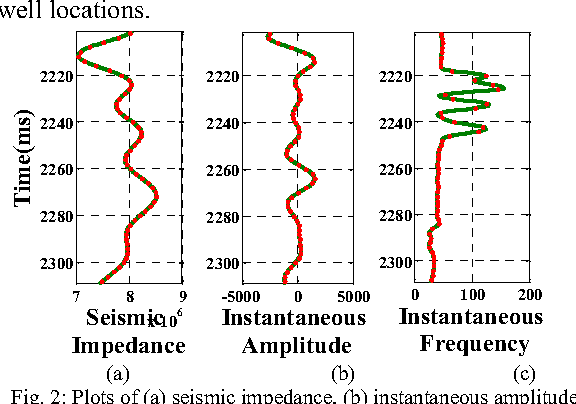
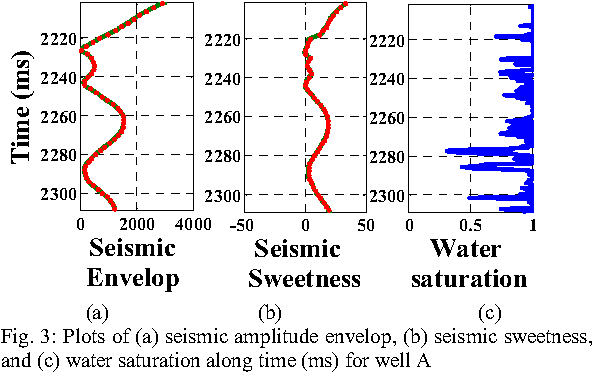
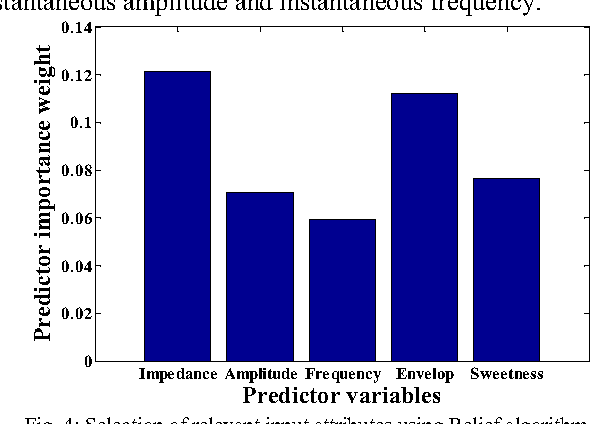
Water saturation is an important property in reservoir engineering domain. Thus, satisfactory classification of water saturation from seismic attributes is beneficial for reservoir characterization. However, diverse and non-linear nature of subsurface attributes makes the classification task difficult. In this context, this paper proposes a generalized Support Vector Data Description (SVDD) based novel classification framework to classify water saturation into two classes (Class high and Class low) from three seismic attributes seismic impedance, amplitude envelop, and seismic sweetness. G-metric means and program execution time are used to quantify the performance of the proposed framework along with established supervised classifiers. The documented results imply that the proposed framework is superior to existing classifiers. The present study is envisioned to contribute in further reservoir modeling.
Development of a hybrid learning system based on SVM, ANFIS and domain knowledge: DKFIS
Dec 02, 2016



This paper presents the development of a hybrid learning system based on Support Vector Machines (SVM), Adaptive Neuro-Fuzzy Inference System (ANFIS) and domain knowledge to solve prediction problem. The proposed two-stage Domain Knowledge based Fuzzy Information System (DKFIS) improves the prediction accuracy attained by ANFIS alone. The proposed framework has been implemented on a noisy and incomplete dataset acquired from a hydrocarbon field located at western part of India. Here, oil saturation has been predicted from four different well logs i.e. gamma ray, resistivity, density, and clay volume. In the first stage, depending on zero or near zero and non-zero oil saturation levels the input vector is classified into two classes (Class 0 and Class 1) using SVM. The classification results have been further fine-tuned applying expert knowledge based on the relationship among predictor variables i.e. well logs and target variable - oil saturation. Second, an ANFIS is designed to predict non-zero (Class 1) oil saturation values from predictor logs. The predicted output has been further refined based on expert knowledge. It is apparent from the experimental results that the expert intervention with qualitative judgment at each stage has rendered the prediction into the feasible and realistic ranges. The performance analysis of the prediction in terms of four performance metrics such as correlation coefficient (CC), root mean square error (RMSE), and absolute error mean (AEM), scatter index (SI) has established DKFIS as a useful tool for reservoir characterization.
A novel multiclassSVM based framework to classify lithology from well logs: a real-world application
Dec 02, 2016
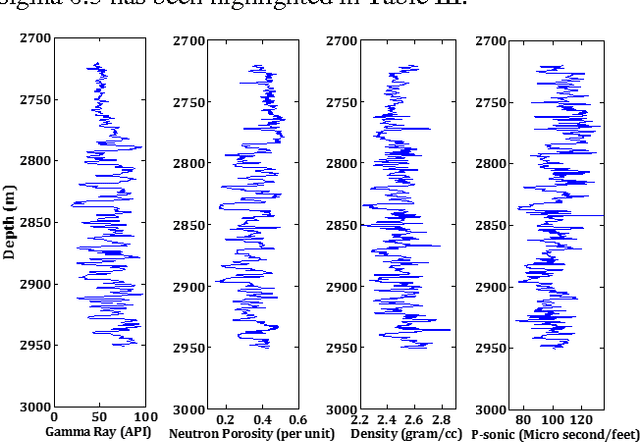
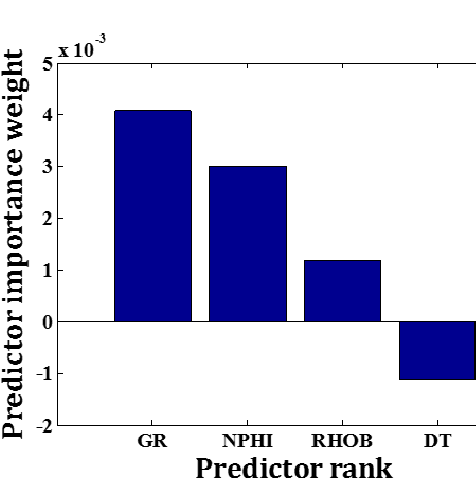
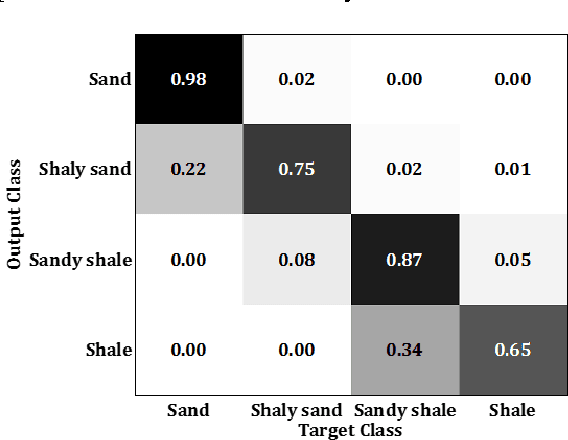
Support vector machines (SVMs) have been recognized as a potential tool for supervised classification analyses in different domains of research. In essence, SVM is a binary classifier. Therefore, in case of a multiclass problem, the problem is divided into a series of binary problems which are solved by binary classifiers, and finally the classification results are combined following either the one-against-one or one-against-all strategies. In this paper, an attempt has been made to classify lithology using a multiclass SVM based framework using well logs as predictor variables. Here, the lithology is classified into four classes such as sand, shaly sand, sandy shale and shale based on the relative values of sand and shale fractions as suggested by an expert geologist. The available dataset consisting well logs (gamma ray, neutron porosity, density, and P-sonic) and class information from four closely spaced wells from an onshore hydrocarbon field is divided into training and testing sets. We have used one-against-all strategy to combine the results of multiple binary classifiers. The reported results established the superiority of multiclass SVM compared to other classifiers in terms of classification accuracy. The selection of kernel function and associated parameters has also been investigated here. It can be envisaged from the results achieved in this study that the proposed framework based on multiclass SVM can further be used to solve classification problems. In future research endeavor, seismic attributes can be introduced in the framework to classify the lithology throughout a study area from seismic inputs.
A One class Classifier based Framework using SVDD : Application to an Imbalanced Geological Dataset
Dec 02, 2016
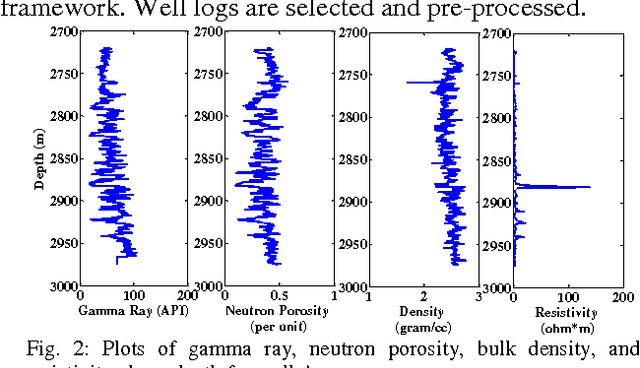


Evaluation of hydrocarbon reservoir requires classification of petrophysical properties from available dataset. However, characterization of reservoir attributes is difficult due to the nonlinear and heterogeneous nature of the subsurface physical properties. In this context, present study proposes a generalized one class classification framework based on Support Vector Data Description (SVDD) to classify a reservoir characteristic water saturation into two classes (Class high and Class low) from four logs namely gamma ray, neutron porosity, bulk density, and P sonic using an imbalanced dataset. A comparison is carried out among proposed framework and different supervised classification algorithms in terms of g metric means and execution time. Experimental results show that proposed framework has outperformed other classifiers in terms of these performance evaluators. It is envisaged that the classification analysis performed in this study will be useful in further reservoir modeling.
Well Tops Guided Prediction of Reservoir Properties using Modular Neural Network Concept A Case Study from Western Onshore, India
Sep 23, 2015This paper proposes a complete framework consisting pre-processing, modeling, and post-processing stages to carry out well tops guided prediction of a reservoir property (sand fraction) from three seismic attributes (seismic impedance, instantaneous amplitude, and instantaneous frequency) using the concept of modular artificial neural network (MANN). The data set used in this study comprising three seismic attributes and well log data from eight wells, is acquired from a western onshore hydrocarbon field of India. Firstly, the acquired data set is integrated and normalized. Then, well log analysis and segmentation of the total depth range into three different units (zones) separated by well tops are carried out. Secondly, three different networks are trained corresponding to three different zones using combined data set of seven wells and then trained networks are validated using the remaining test well. The target property of the test well is predicted using three different tuned networks corresponding to three zones; and then the estimated values obtained from three different networks are concatenated to represent the predicted log along the complete depth range of the testing well. The application of multiple simpler networks instead of a single one improves the prediction accuracy in terms of performance metrics such as correlation coefficient, root mean square error, absolute error mean and program execution time.
Quantification of sand fraction from seismic attributes using Neuro-Fuzzy approach
Sep 23, 2015In this paper, we illustrate the modeling of a reservoir property (sand fraction) from seismic attributes namely seismic impedance, seismic amplitude, and instantaneous frequency using Neuro-Fuzzy (NF) approach. Input dataset includes 3D post-stacked seismic attributes and six well logs acquired from a hydrocarbon field located in the western coast of India. Presence of thin sand and shale layers in the basin area makes the modeling of reservoir characteristic a challenging task. Though seismic data is helpful in extrapolation of reservoir properties away from boreholes; yet, it could be challenging to delineate thin sand and shale reservoirs using seismic data due to its limited resolvability. Therefore, it is important to develop state-of-art intelligent methods for calibrating a nonlinear mapping between seismic data and target reservoir variables. Neural networks have shown its potential to model such nonlinear mappings; however, uncertainties associated with the model and datasets are still a concern. Hence, introduction of Fuzzy Logic (FL) is beneficial for handling these uncertainties. More specifically, hybrid variants of Artificial Neural Network (ANN) and fuzzy logic, i.e., NF methods, are capable for the modeling reservoir characteristics by integrating the explicit knowledge representation power of FL with the learning ability of neural networks. The documented results in this study demonstrate acceptable resemblance between target and predicted variables, and hence, encourage the application of integrated machine learning approaches such as Neuro-Fuzzy in reservoir characterization domain. Furthermore, visualization of the variation of sand probability in the study area would assist in identifying placement of potential wells for future drilling operations.