 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Fine-grained Image Classification with Generative Adversarial Networks and Facial Landmark Detection
Aug 28, 2021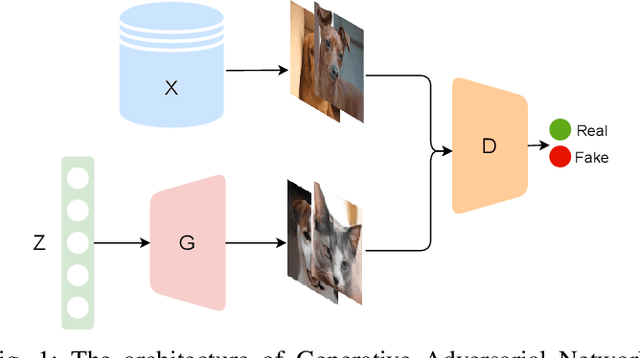
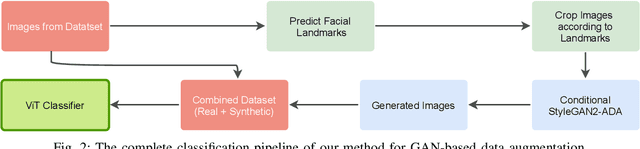


Fine-grained classification remains a challenging task because distinguishing categories needs learning complex and local differences. Diversity in the pose, scale, and position of objects in an image makes the problem even more difficult. Although the recent Vision Transformer models achieve high performance, they need an extensive volume of input data. To encounter this problem, we made the best use of GAN-based data augmentation to generate extra dataset instances. Oxford-IIIT Pets was our dataset of choice for this experiment. It consists of 37 breeds of cats and dogs with variations in scale, poses, and lighting, which intensifies the difficulty of the classification task. Furthermore, we enhanced the performance of the recent Generative Adversarial Network (GAN), StyleGAN2-ADA model to generate more realistic images while preventing overfitting to the training set. We did this by training a customized version of MobileNetV2 to predict animal facial landmarks; then, we cropped images accordingly. Lastly, we combined the synthetic images with the original dataset and compared our proposed method with standard GANs augmentation and no augmentation with different subsets of training data. We validated our work by evaluating the accuracy of fine-grained image classification on the recent Vision Transformer (ViT) Model.