 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMunsit at NADI 2025 Shared Task 2: Pushing the Boundaries of Multidialectal Arabic ASR with Weakly Supervised Pretraining and Continual Supervised Fine-tuning
Aug 12, 2025Automatic speech recognition (ASR) plays a vital role in enabling natural human-machine interaction across applications such as virtual assistants, industrial automation, customer support, and real-time transcription. However, developing accurate ASR systems for low-resource languages like Arabic remains a significant challenge due to limited labeled data and the linguistic complexity introduced by diverse dialects. In this work, we present a scalable training pipeline that combines weakly supervised learning with supervised fine-tuning to develop a robust Arabic ASR model. In the first stage, we pretrain the model on 15,000 hours of weakly labeled speech covering both Modern Standard Arabic (MSA) and various Dialectal Arabic (DA) variants. In the subsequent stage, we perform continual supervised fine-tuning using a mixture of filtered weakly labeled data and a small, high-quality annotated dataset. Our approach achieves state-of-the-art results, ranking first in the multi-dialectal Arabic ASR challenge. These findings highlight the effectiveness of weak supervision paired with fine-tuning in overcoming data scarcity and delivering high-quality ASR for low-resource, dialect-rich languages.
Advancing Arabic Speech Recognition Through Large-Scale Weakly Supervised Learning
Apr 16, 2025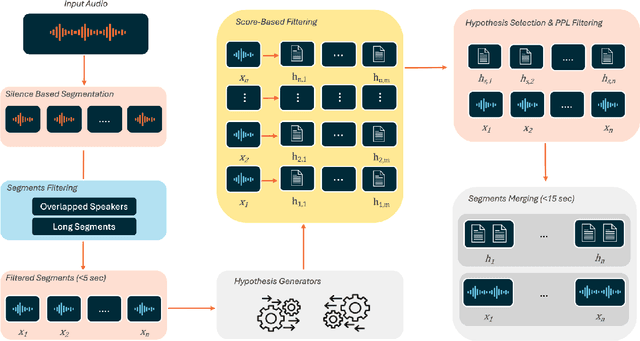

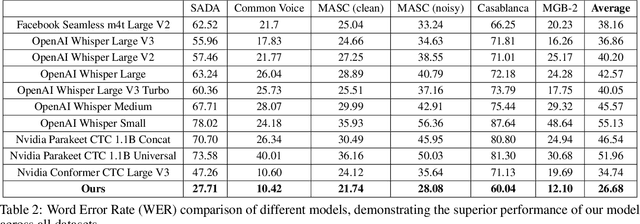
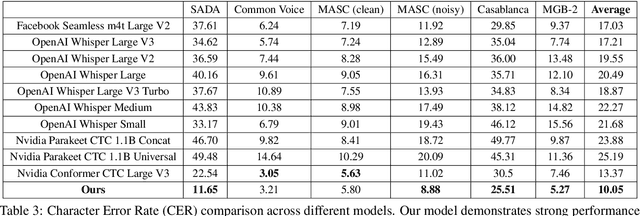
Automatic speech recognition (ASR) is crucial for human-machine interaction in diverse applications like conversational agents, industrial robotics, call center automation, and automated subtitling. However, developing high-performance ASR models remains challenging, particularly for low-resource languages like Arabic, due to the scarcity of large, labeled speech datasets, which are costly and labor-intensive to produce. In this work, we employ weakly supervised learning to train an Arabic ASR model using the Conformer architecture. Our model is trained from scratch on 15,000 hours of weakly annotated speech data covering both Modern Standard Arabic (MSA) and Dialectal Arabic (DA), eliminating the need for costly manual transcriptions. Despite the absence of human-verified labels, our approach attains state-of-the-art (SOTA) performance, exceeding all previous efforts in the field of Arabic ASR on the standard benchmarks. By demonstrating the effectiveness of weak supervision as a scalable, cost-efficient alternative to traditional supervised approaches, paving the way for improved ASR systems in low resource settings.
Speech Bandwidth Expansion Via High Fidelity Generative Adversarial Networks
Jul 29, 2024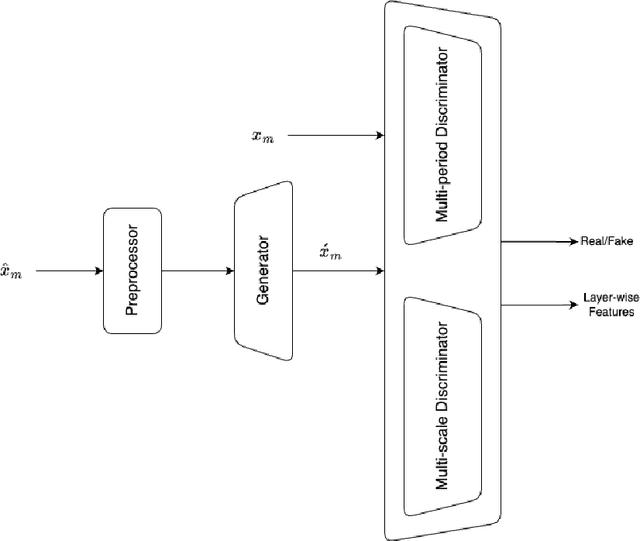
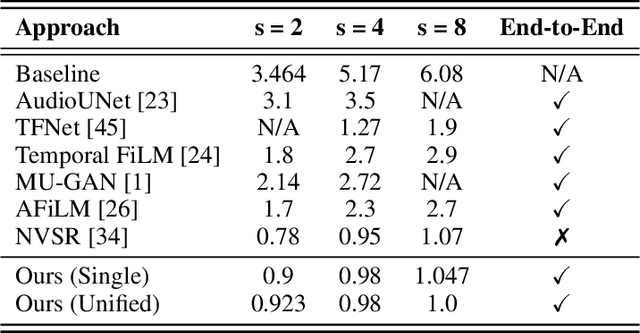
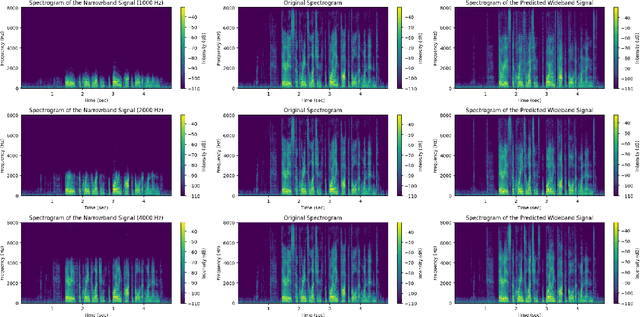
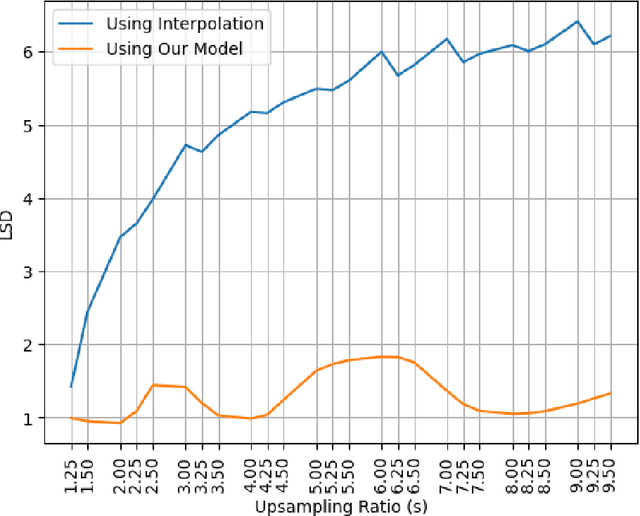
Speech bandwidth expansion is crucial for expanding the frequency range of low-bandwidth speech signals, thereby improving audio quality, clarity and perceptibility in digital applications. Its applications span telephony, compression, text-to-speech synthesis, and speech recognition. This paper presents a novel approach using a high-fidelity generative adversarial network, unlike cascaded systems, our system is trained end-to-end on paired narrowband and wideband speech signals. Our method integrates various bandwidth upsampling ratios into a single unified model specifically designed for speech bandwidth expansion applications. Our approach exhibits robust performance across various bandwidth expansion factors, including those not encountered during training, demonstrating zero-shot capability. To the best of our knowledge, this is the first work to showcase this capability. The experimental results demonstrate that our method outperforms previous end-to-end approaches, as well as interpolation and traditional techniques, showcasing its effectiveness in practical speech enhancement applications.
AraSpell: A Deep Learning Approach for Arabic Spelling Correction
May 11, 2024
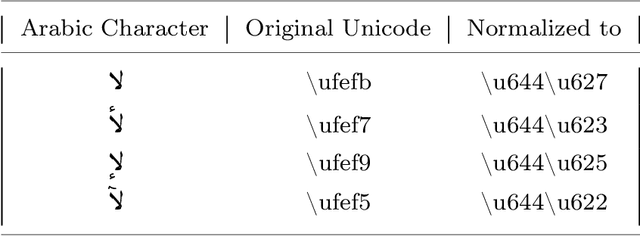
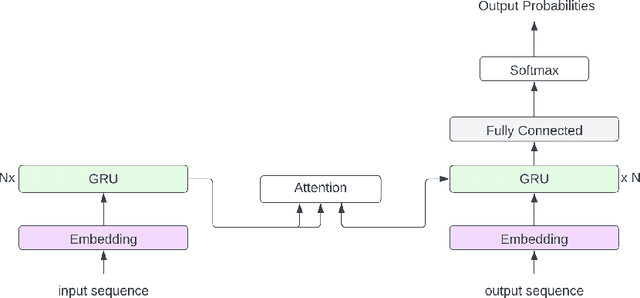
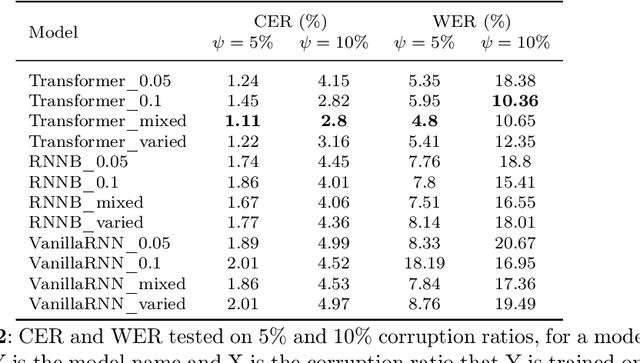
Spelling correction is the task of identifying spelling mistakes, typos, and grammatical mistakes in a given text and correcting them according to their context and grammatical structure. This work introduces "AraSpell," a framework for Arabic spelling correction using different seq2seq model architectures such as Recurrent Neural Network (RNN) and Transformer with artificial data generation for error injection, trained on more than 6.9 Million Arabic sentences. Thorough experimental studies provide empirical evidence of the effectiveness of the proposed approach, which achieved 4.8% and 1.11% word error rate (WER) and character error rate (CER), respectively, in comparison with labeled data of 29.72% WER and 5.03% CER. Our approach achieved 2.9% CER and 10.65% WER in comparison with labeled data of 10.02% CER and 50.94% WER. Both of these results are obtained on a test set of 100K sentences.
Proof of Deep Learning: Approaches, Challenges, and Future Directions
Aug 31, 2023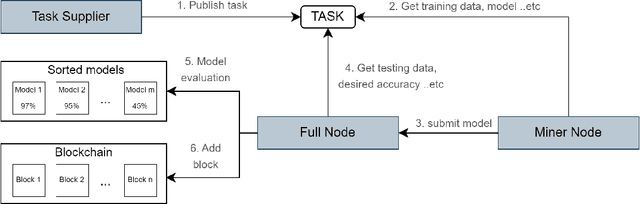
The rise of computational power has led to unprecedented performance gains for deep learning models. As more data becomes available and model architectures become more complex, the need for more computational power increases. On the other hand, since the introduction of Bitcoin as the first cryptocurrency and the establishment of the concept of blockchain as a distributed ledger, many variants and approaches have been proposed. However, many of them have one thing in common, which is the Proof of Work (PoW) consensus mechanism. PoW is mainly used to support the process of new block generation. While PoW has proven its robustness, its main drawback is that it requires a significant amount of processing power to maintain the security and integrity of the blockchain. This is due to applying brute force to solve a hashing puzzle. To utilize the computational power available in useful and meaningful work while keeping the blockchain secure, many techniques have been proposed, one of which is known as Proof of Deep Learning (PoDL). PoDL is a consensus mechanism that uses the process of training a deep learning model as proof of work to add new blocks to the blockchain. In this paper, we survey the various approaches for PoDL. We discuss the different types of PoDL algorithms, their advantages and disadvantages, and their potential applications. We also discuss the challenges of implementing PoDL and future research directions.
AraSpot: Arabic Spoken Command Spotting
Mar 29, 2023



Spoken keyword spotting (KWS) is the task of identifying a keyword in an audio stream and is widely used in smart devices at the edge in order to activate voice assistants and perform hands-free tasks. The task is daunting as there is a need, on the one hand, to achieve high accuracy while at the same time ensuring that such systems continue to run efficiently on low power and possibly limited computational capabilities devices. This work presents AraSpot for Arabic keyword spotting trained on 40 Arabic keywords, using different online data augmentation, and introducing ConformerGRU model architecture. Finally, we further improve the performance of the model by training a text-to-speech model for synthetic data generation. AraSpot achieved a State-of-the-Art SOTA 99.59% result outperforming previous approaches.