 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMethod for Customizable Automated Tagging: Addressing the Problem of Over-tagging and Under-tagging Text Documents
Apr 30, 2020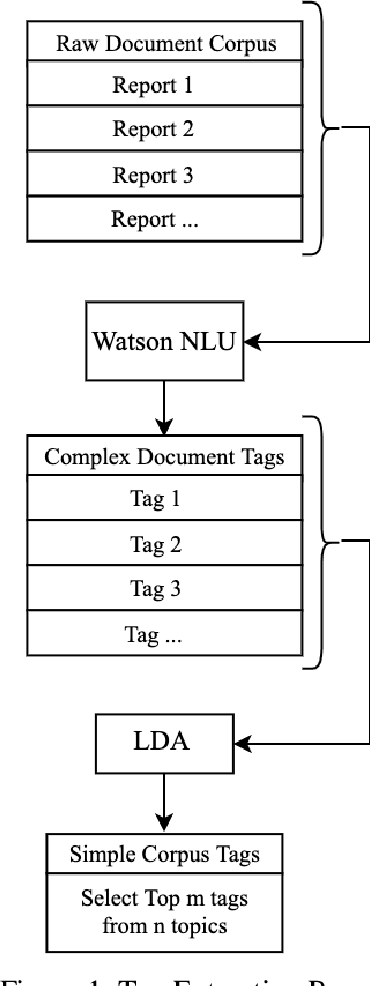
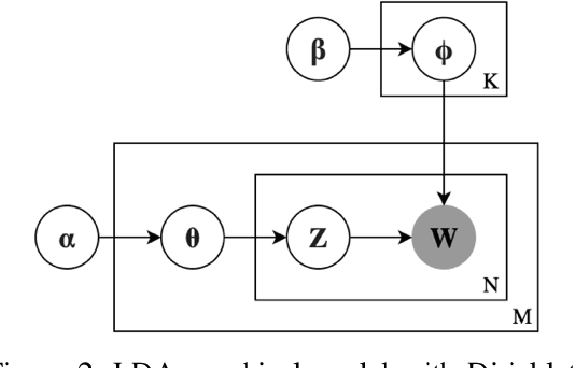
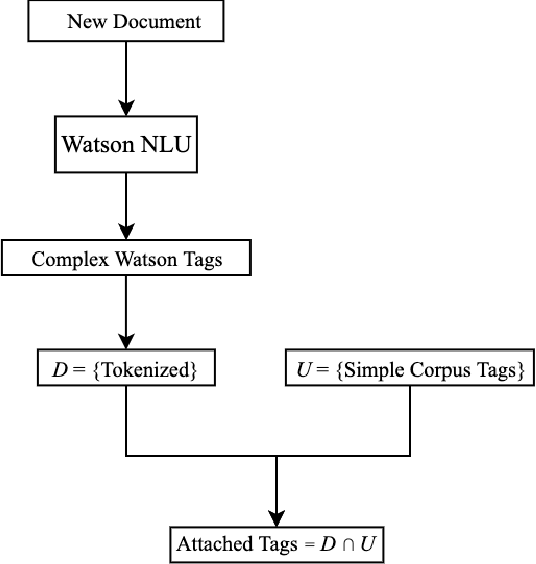
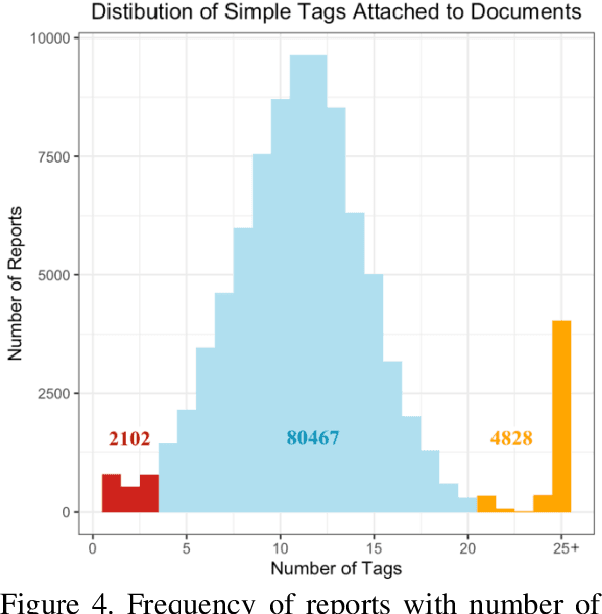
Using author provided tags to predict tags for a new document often results in the overgeneration of tags. In the case where the author doesn't provide any tags, our documents face the severe under-tagging issue. In this paper, we present a method to generate a universal set of tags that can be applied widely to a large document corpus. Using IBM Watson's NLU service, first, we collect keywords/phrases that we call "complex document tags" from 8,854 popular reports in the corpus. We apply LDA model over these complex document tags to generate a set of 765 unique "simple tags". In applying the tags to a corpus of documents, we run each document through the IBM Watson NLU and apply appropriate simple tags. Using only 765 simple tags, our method allows us to tag 87,397 out of 88,583 total documents in the corpus with at least one tag. About 92.1% of the total 87,397 documents are also determined to be sufficiently-tagged. In the end, we discuss the performance of our method and its limitations.