 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised textile defect detection using convolutional neural networks
Nov 30, 2023In this study, we propose a novel motif-based approach for unsupervised textile anomaly detection that combines the benefits of traditional convolutional neural networks with those of an unsupervised learning paradigm. It consists of five main steps: preprocessing, automatic pattern period extraction, patch extraction, features selection and anomaly detection. This proposed approach uses a new dynamic and heuristic method for feature selection which avoids the drawbacks of initialization of the number of filters (neurons) and their weights, and those of the backpropagation mechanism such as the vanishing gradients, which are common practice in the state-of-the-art methods. The design and training of the network are performed in a dynamic and input domain-based manner and, thus, no ad-hoc configurations are required. Before building the model, only the number of layers and the stride are defined. We do not initialize the weights randomly nor do we define the filter size or number of filters as conventionally done in CNN-based approaches. This reduces effort and time spent on hyperparameter initialization and fine-tuning. Only one defect-free sample is required for training and no further labeled data is needed. The trained network is then used to detect anomalies on defective fabric samples. We demonstrate the effectiveness of our approach on the Patterned Fabrics benchmark dataset. Our algorithm yields reliable and competitive results (on recall, precision, accuracy and f1- measure) compared to state-of-the-art unsupervised approaches, in less time, with efficient training in a single epoch and a lower computational cost.
Unreasonable Effectiveness of Last Hidden Layer Activations
Feb 15, 2022
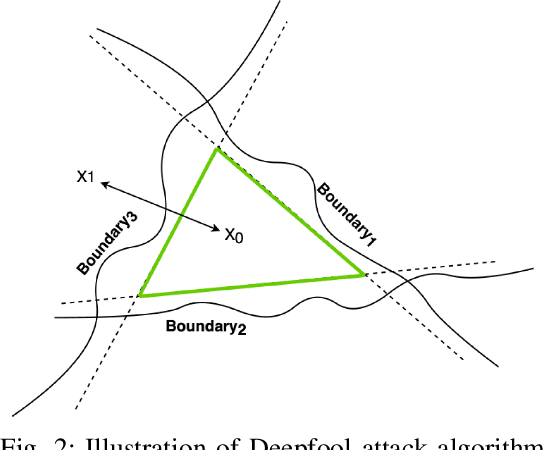
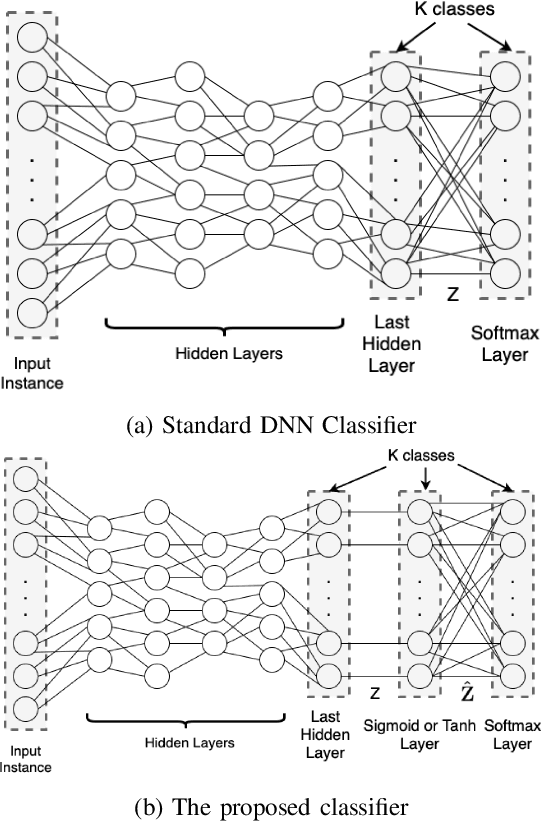
In standard Deep Neural Network (DNN) based classifiers, the general convention is to omit the activation function in the last (output) layer and directly apply the softmax function on the logits to get the probability scores of each class. In this type of architectures, the loss value of the classifier against any output class is directly proportional to the difference between the final probability score and the label value of the associated class. Standard White-box adversarial evasion attacks, whether targeted or untargeted, mainly try to exploit the gradient of the model loss function to craft adversarial samples and fool the model. In this study, we show both mathematically and experimentally that using some widely known activation functions in the output layer of the model with high temperature values has the effect of zeroing out the gradients for both targeted and untargeted attack cases, preventing attackers from exploiting the model's loss function to craft adversarial samples. We've experimentally verified the efficacy of our approach on MNIST (Digit), CIFAR10 datasets. Detailed experiments confirmed that our approach substantially improves robustness against gradient-based targeted and untargeted attack threats. And, we showed that the increased non-linearity at the output layer has some additional benefits against some other attack methods like Deepfool attack.
Exploiting epistemic uncertainty of the deep learning models to generate adversarial samples
Feb 13, 2021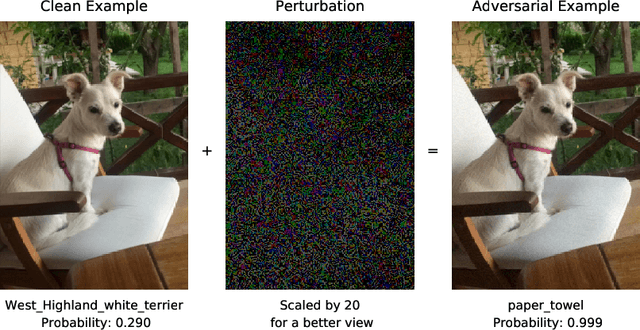
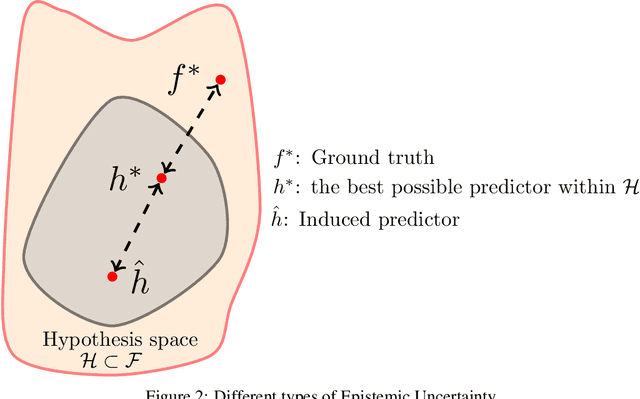

Deep neural network architectures are considered to be robust to random perturbations. Nevertheless, it was shown that they could be severely vulnerable to slight but carefully crafted perturbations of the input, termed as adversarial samples. In recent years, numerous studies have been conducted in this new area called "Adversarial Machine Learning" to devise new adversarial attacks and to defend against these attacks with more robust DNN architectures. However, almost all the research work so far has been concentrated on utilising model loss function to craft adversarial examples or create robust models. This study explores the usage of quantified epistemic uncertainty obtained from Monte-Carlo Dropout Sampling for adversarial attack purposes by which we perturb the input to the areas where the model has not seen before. We proposed new attack ideas based on the epistemic uncertainty of the model. Our results show that our proposed hybrid attack approach increases the attack success rates from 82.59% to 85.40%, 82.86% to 89.92% and 88.06% to 90.03% on MNIST Digit, MNIST Fashion and CIFAR-10 datasets, respectively.
Closeness and Uncertainty Aware Adversarial Examples Detection in Adversarial Machine Learning
Dec 11, 2020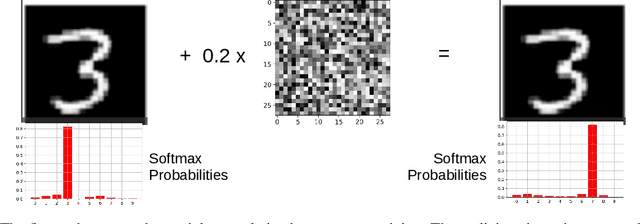
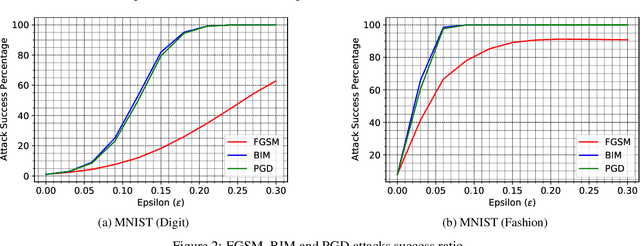
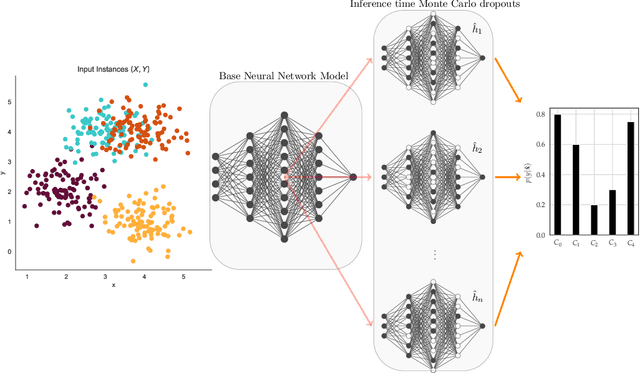
Deep neural network (DNN) architectures are considered to be robust to random perturbations. Nevertheless, it was shown that they could be severely vulnerable to slight but carefully crafted perturbations of the input, which are termed as adversarial samples. In recent years, numerous studies have been conducted to increase the reliability of DNN models by distinguishing adversarial samples from regular inputs. In this work, we explore and assess the usage of 2 different groups of metrics in detecting adversarial samples: the ones which are based on the uncertainty estimation using Monte-Carlo Dropout Sampling and the ones which are based on closeness measures in the subspace of deep features extracted by the model. We also introduce a new feature for adversarial detection, and we show that the performances of all these metrics heavily depend on the strength of the attack being used.