 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolInterviews -- A Dataset of German Politician Public Broadcast Interviews
Jan 08, 2025This paper presents a novel dataset of public broadcast interviews featuring high-ranking German politicians. The interviews were sourced from YouTube, transcribed, processed for speaker identification, and stored in a tidy and open format. The dataset comprises 99 interviews with 33 different German politicians across five major interview formats, containing a total of 28,146 sentences. As the first of its kind, this dataset offers valuable opportunities for research on various aspects of political communication in the (German) political contexts, such as agenda-setting, interviewer dynamics, or politicians' self-presentation.
From Measurement Instruments to Data: Leveraging Theory-Driven Synthetic Training Data for Classifying Social Constructs
Oct 17, 2024



Computational text classification is a challenging task, especially for multi-dimensional social constructs. Recently, there has been increasing discussion that synthetic training data could enhance classification by offering examples of how these constructs are represented in texts. In this paper, we systematically examine the potential of theory-driven synthetic training data for improving the measurement of social constructs. In particular, we explore how researchers can transfer established knowledge from measurement instruments in the social sciences, such as survey scales or annotation codebooks, into theory-driven generation of synthetic data. Using two studies on measuring sexism and political topics, we assess the added value of synthetic training data for fine-tuning text classification models. Although the results of the sexism study were less promising, our findings demonstrate that synthetic data can be highly effective in reducing the need for labeled data in political topic classification. With only a minimal drop in performance, synthetic data allows for substituting large amounts of labeled data. Furthermore, theory-driven synthetic data performed markedly better than data generated without conceptual information in mind.
ValiTex -- a unified validation framework for computational text-based measures of social science constructs
Jul 10, 2023
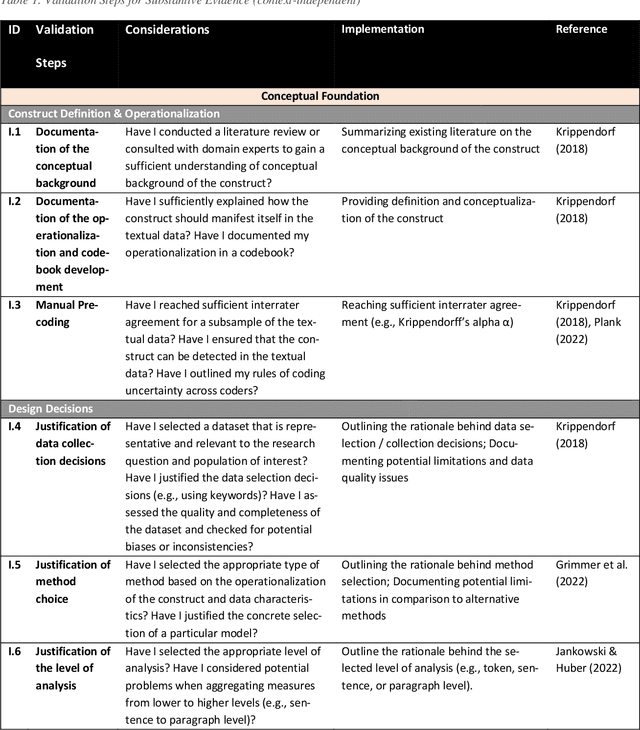


Guidance on how to validate computational text-based measures of social science constructs is fragmented. Whereas scholars are generally acknowledging the importance of validating their text-based measures, they often lack common terminology and a unified framework to do so. This paper introduces a new validation framework called ValiTex, designed to assist scholars to measure social science constructs based on textual data. The framework draws on a long-established tradition within psychometrics while extending the framework for the purpose of computational text analysis. ValiTex consists of two components, a conceptual model, and a dynamic checklist. Whereas the conceptual model provides a general structure along distinct phases on how to approach validation, the dynamic checklist defines specific validation steps and provides guidance on which steps might be considered recommendable (i.e., providing relevant and necessary validation evidence) or optional (i.e., useful for providing additional supporting validation evidence. The utility of the framework is demonstrated by applying it to a use case of detecting sexism from social media data.