 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose Manipulation with Identity Preservation
Apr 20, 2020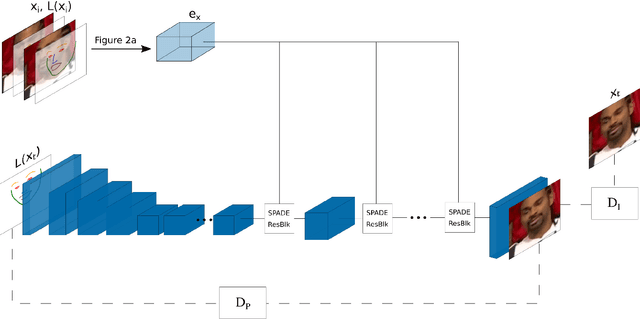
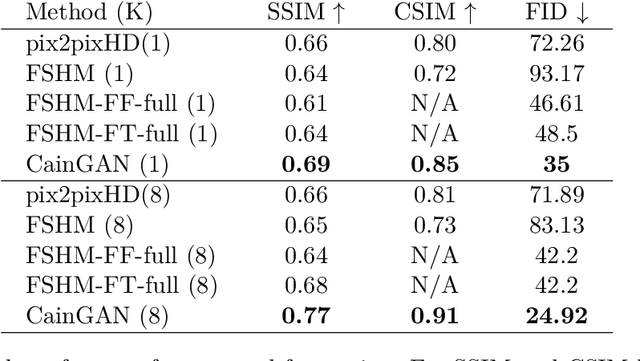
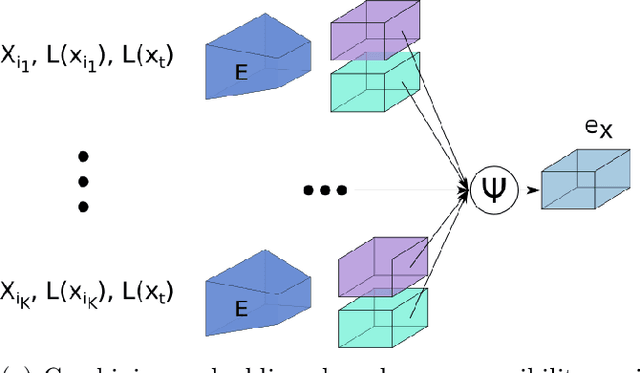
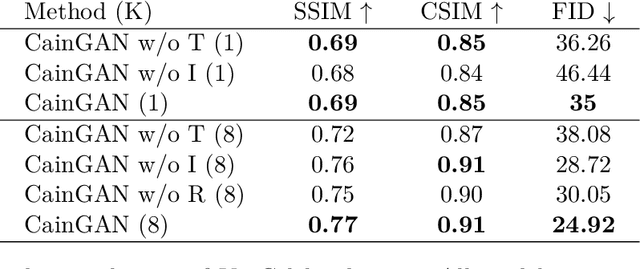
This paper describes a new model which generates images in novel poses e.g. by altering face expression and orientation, from just a few instances of a human subject. Unlike previous approaches which require large datasets of a specific person for training, our approach may start from a scarce set of images, even from a single image. To this end, we introduce Character Adaptive Identity Normalization GAN (CainGAN) which uses spatial characteristic features extracted by an embedder and combined across source images. The identity information is propagated throughout the network by applying conditional normalization. After extensive adversarial training, CainGAN receives figures of faces from a certain individual and produces new ones while preserving the person's identity. Experimental results show that the quality of generated images scales with the size of the input set used during inference. Furthermore, quantitative measurements indicate that CainGAN performs better compared to other methods when training data is limited.
* 9 pages, journal article