 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePuffin: pitch-synchronous neural waveform generation for fullband speech on modest devices
Nov 25, 2022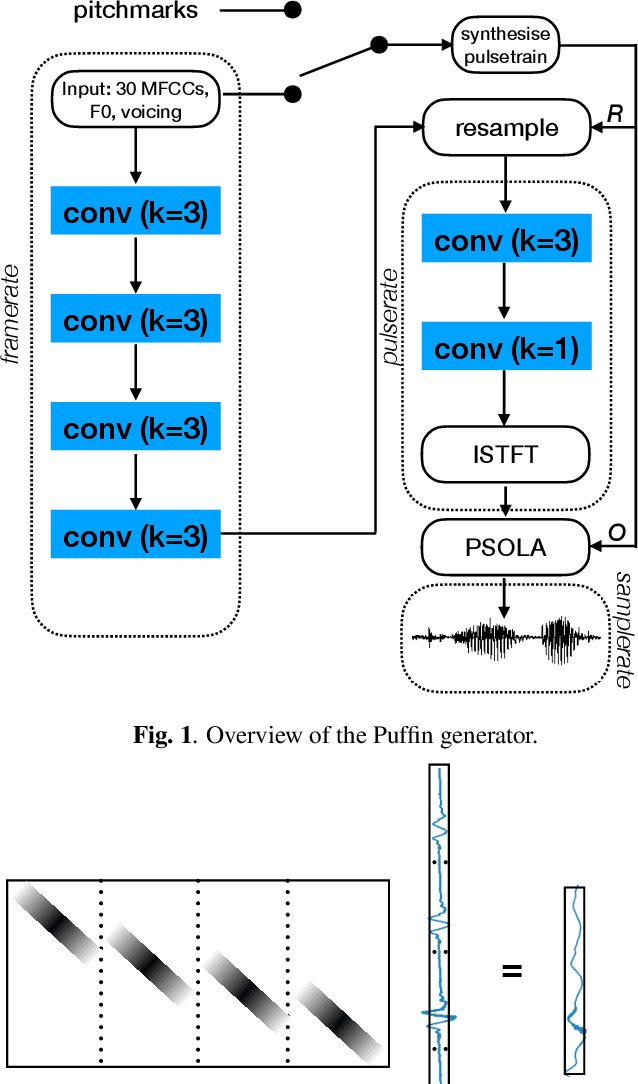
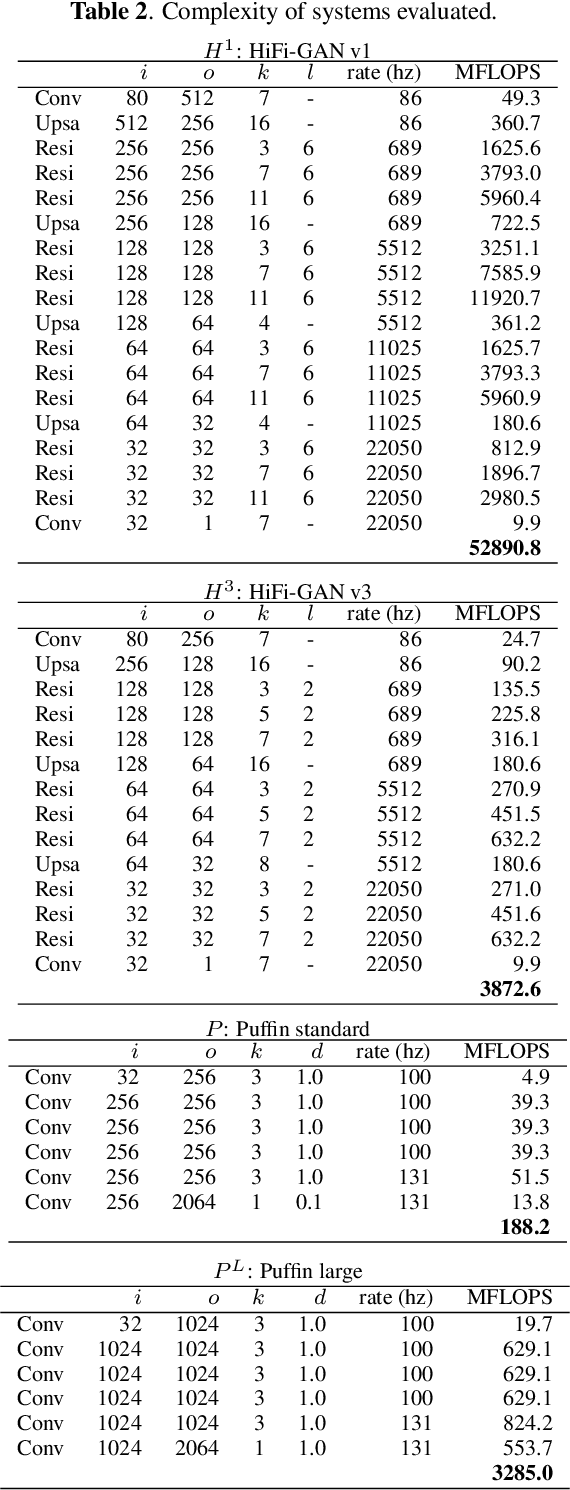
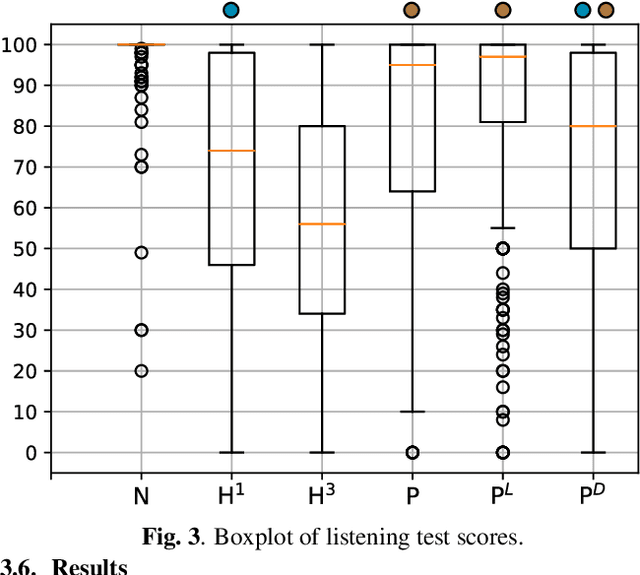
We present a neural vocoder designed with low-powered Alternative and Augmentative Communication devices in mind. By combining elements of successful modern vocoders with established ideas from an older generation of technology, our system is able to produce high quality synthetic speech at 48kHz on devices where neural vocoders are otherwise prohibitively complex. The system is trained adversarially using differentiable pitch synchronous overlap add, and reduces complexity by relying on pitch synchronous Inverse Short-Time Fourier Transform (ISTFT) to generate speech samples. Our system achieves comparable quality with a strong (HiFi-GAN) baseline while using only a fraction of the compute. We present results of a perceptual evaluation as well as an analysis of system complexity.