 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling the Training Dynamics of ReLU Networks through a Linear Lens
Nov 07, 2025Deep neural networks, particularly those employing Rectified Linear Units (ReLU), are often perceived as complex, high-dimensional, non-linear systems. This complexity poses a significant challenge to understanding their internal learning mechanisms. In this work, we propose a novel analytical framework that recasts a multi-layer ReLU network into an equivalent single-layer linear model with input-dependent "effective weights". For any given input sample, the activation pattern of ReLU units creates a unique computational path, effectively zeroing out a subset of weights in the network. By composing the active weights across all layers, we can derive an effective weight matrix, $W_{\text{eff}}(x)$, that maps the input directly to the output for that specific sample. We posit that the evolution of these effective weights reveals fundamental principles of representation learning. Our work demonstrates that as training progresses, the effective weights corresponding to samples from the same class converge, while those from different classes diverge. By tracking the trajectories of these sample-wise effective weights, we provide a new lens through which to interpret the formation of class-specific decision boundaries and the emergence of semantic representations within the network.
AugOp: Inject Transformation into Neural Operator
Nov 23, 2022



In this paper, we propose a simple and general approach to augment regular convolution operator by injecting extra group-wise transformation during training and recover it during inference. Extra transformation is carefully selected to ensure it can be merged with regular convolution in each group and will not change the topological structure of regular convolution during inference. Compared with regular convolution operator, our approach (AugConv) can introduce larger learning capacity to improve model performance during training but will not increase extra computational overhead for model deployment. Based on ResNet, we utilize AugConv to build convolutional neural networks named AugResNet. Result on image classification dataset Cifar-10 shows that AugResNet outperforms its baseline in terms of model performance.
AugShuffleNet: Improve ShuffleNetV2 via More Information Communication
Mar 13, 2022



Based on ShuffleNetV2, we build a more powerful and efficient model family, termed as AugShuffleNets, by introducing higher frequency of cross-layer information communication for better model performance. Evaluated on the CIFAR-10 and CIFAR-100 datasets, AugShuffleNet consistently outperforms ShuffleNetV2 in terms of accuracy, with less computational cost, fewer parameter count.
Dynamic Clone Transformer for Efficient Convolutional Neural Netwoks
Jun 12, 2021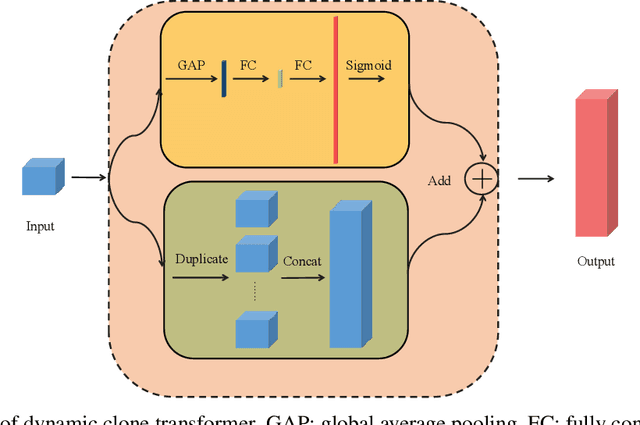



Convolutional networks (ConvNets) have shown impressive capability to solve various vision tasks. Nevertheless, the trade-off between performance and efficiency is still a challenge for a feasible model deployment on resource-constrained platforms. In this paper, we introduce a novel concept termed multi-path fully connected pattern (MPFC) to rethink the interdependencies of topology pattern, accuracy and efficiency for ConvNets. Inspired by MPFC, we further propose a dual-branch module named dynamic clone transformer (DCT) where one branch generates multiple replicas from inputs and another branch reforms those clones through a series of difference vectors conditional on inputs itself to produce more variants. This operation allows the self-expansion of channel-wise information in a data-driven way with little computational cost while providing sufficient learning capacity, which is a potential unit to replace computationally expensive pointwise convolution as an expansion layer in the bottleneck structure.