 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTS-RGBD Dataset: a Novel Dataset for Theatre Scenes Description for People with Visual Impairments
Aug 02, 2023Computer vision was long a tool used for aiding visually impaired people to move around their environment and avoid obstacles and falls. Solutions are limited to either indoor or outdoor scenes, which limits the kind of places and scenes visually disabled people can be in, including entertainment places such as theatres. Furthermore, most of the proposed computer-vision-based methods rely on RGB benchmarks to train their models resulting in a limited performance due to the absence of the depth modality. In this paper, we propose a novel RGB-D dataset containing theatre scenes with ground truth human actions and dense captions annotations for image captioning and human action recognition: TS-RGBD dataset. It includes three types of data: RGB, depth, and skeleton sequences, captured by Microsoft Kinect. We test image captioning models on our dataset as well as some skeleton-based human action recognition models in order to extend the range of environment types where a visually disabled person can be, by detecting human actions and textually describing appearances of regions of interest in theatre scenes.
Theater Aid System for the Visually Impaired Through Transfer Learning of Spatio-Temporal Graph Convolution Networks
Jun 28, 2023The aim of this research is to recognize human actions performed on stage to aid visually impaired and blind individuals. To achieve this, we have created a theatre human action recognition system that uses skeleton data captured by depth image as input. We collected new samples of human actions in a theatre environment, and then tested the transfer learning technique with three pre-trained Spatio-Temporal Graph Convolution Networks for skeleton-based human action recognition: the spatio-temporal graph convolution network, the two-stream adaptive graph convolution network, and the multi-scale disentangled unified graph convolution network. We selected the NTU-RGBD human action benchmark as the source domain and used our collected dataset as the target domain. We analyzed the transferability of the pre-trained models and proposed two configurations to apply and adapt the transfer learning technique to the diversity between the source and target domains. The use of transfer learning helped to improve the performance of the human action system within the context of theatre. The results indicate that Spatio-Temporal Graph Convolution Networks is positively transferred, and there was an improvement in performance compared to the baseline without transfer learning.
Semantic Labeling of Human Action For Visually Impaired And Blind People Scene Interaction
Jan 12, 2022
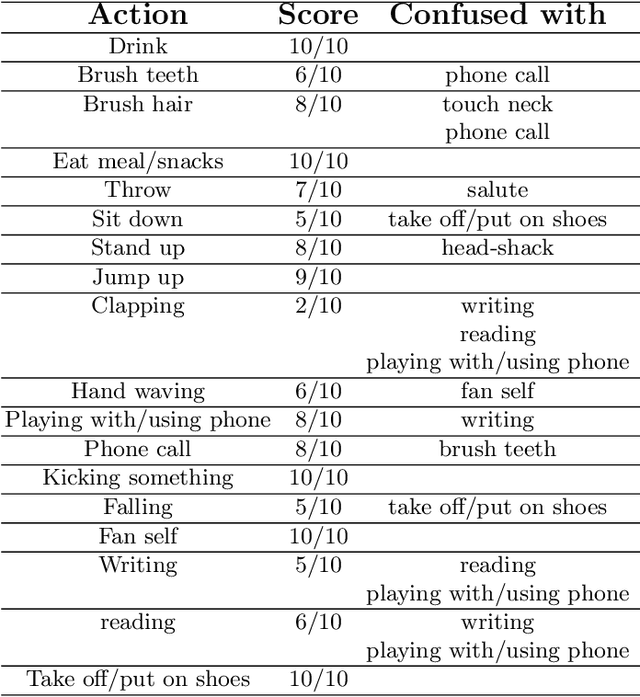

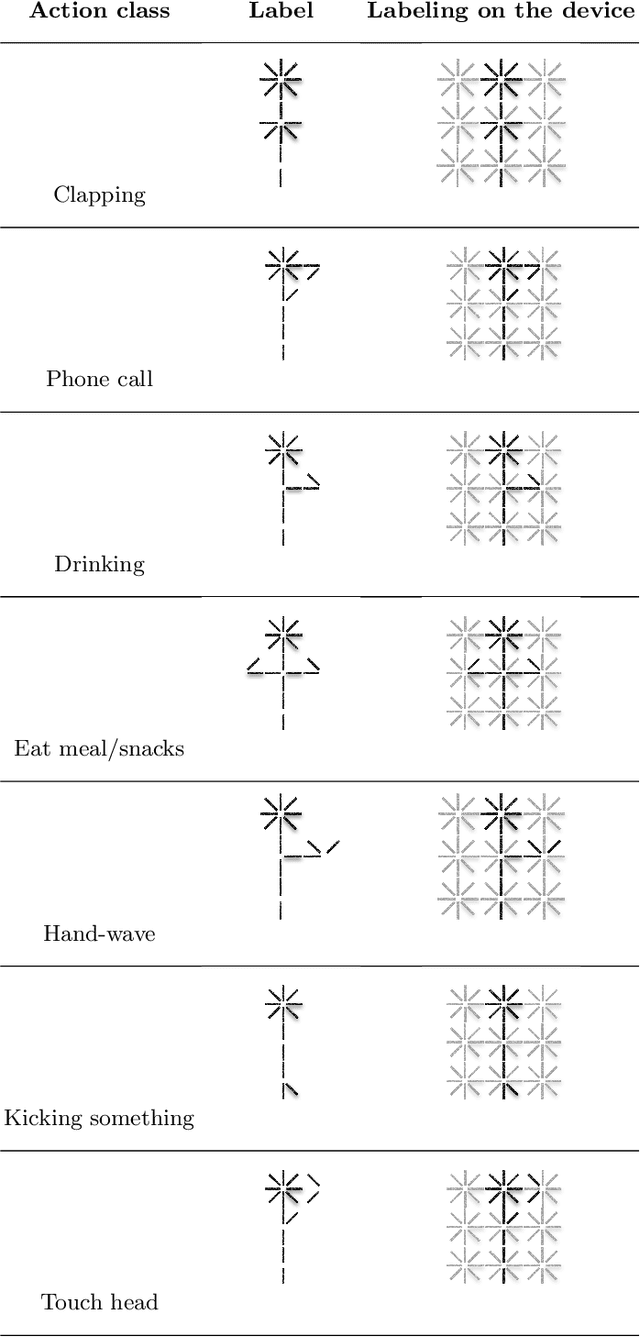
The aim of this work is to contribute to the development of a tactile device for visually impaired and blind persons in order to let them to understand actions of the surrounding people and to interact with them. First, based on the state-of-the-art methods of human action recognition from RGB-D sequences, we use the skeleton information provided by Kinect, with the disentangled and unified multi-scale Graph Convolutional (MS-G3D) model to recognize the performed actions. We tested this model on real scenes and found some of constraints and limitations. Next, we apply a fusion between skeleton modality with MS-G3D and depth modality with CNN in order to bypass the discussed limitations. Third, the recognized actions are labeled semantically and will be mapped into an output device perceivable by the touch sense.