 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeItem-Graph2vec: a Efficient and Effective Approach using Item Co-occurrence Graph Embedding for Collaborative Filtering
Oct 22, 2023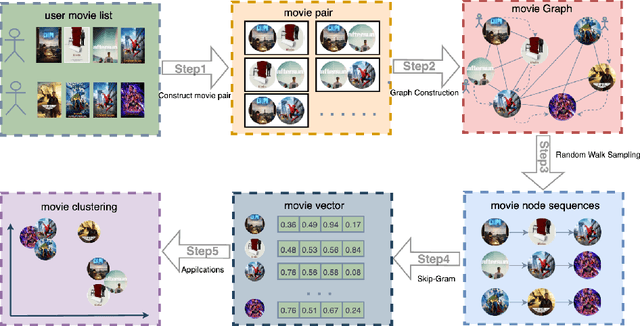
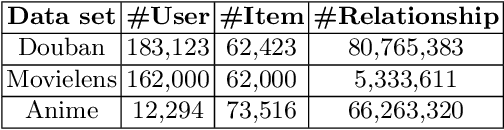
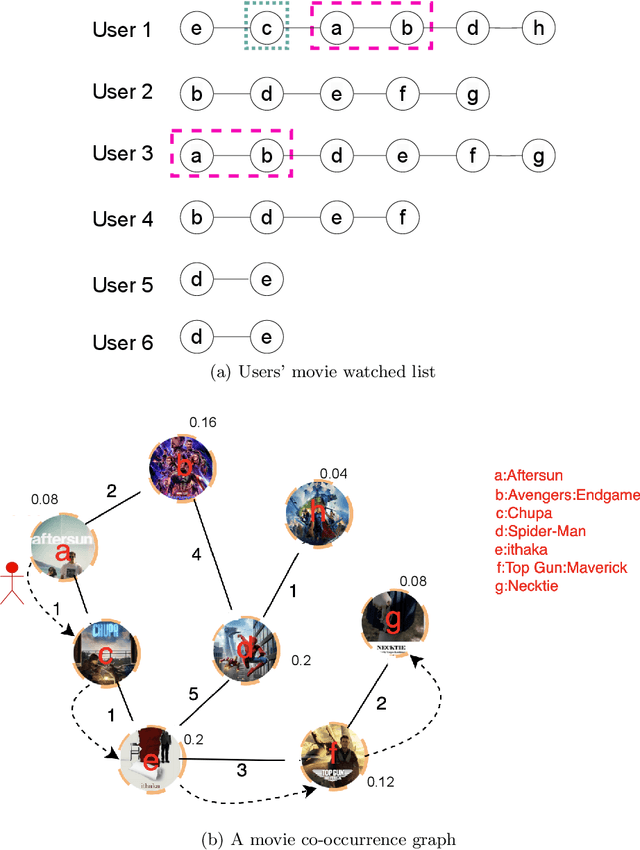
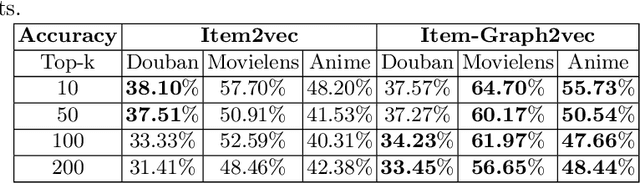
Current item-item collaborative filtering algorithms based on artificial neural network, such as Item2vec, have become ubiquitous and are widely applied in the modern recommender system. However, these approaches do not apply to the large-scale item-based recommendation system because of their extremely long training time. To overcome the shortcoming that current algorithms have high training time costs and poor stability when dealing with large-scale data sets, the item graph embedding algorithm Item-Graph2vec is described here. This algorithm transforms the users' shopping list into a item co-occurrence graph, obtains item sequences through randomly travelling on this co-occurrence graph and finally trains item vectors through sequence samples. We posit that because of the stable size of item, the size and density of the item co-occurrence graph change slightly with the increase in the training corpus. Therefore, Item-Graph2vec has a stable runtime on the large scale data set, and its performance advantage becomes more and more obvious with the growth of the training corpus. Extensive experiments conducted on real-world data sets demonstrate that Item-Graph2vec outperforms Item2vec by 3 times in terms of efficiency on douban data set, while the error generated by the random walk sampling is small.