 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrop identification using deep learning on LUCAS crop cover photos
May 08, 2023Crop classification via deep learning on ground imagery can deliver timely and accurate crop-specific information to various stakeholders. Dedicated ground-based image acquisition exercises can help to collect data in data scarce regions, improve control on timing of collection, or when study areas are to small to monitor via satellite. Automatic labelling is essential when collecting large volumes of data. One such data collection is the EU's Land Use Cover Area frame Survey (LUCAS), and in particular, the recently published LUCAS Cover photos database. The aim of this paper is to select and publish a subset of LUCAS Cover photos for 12 mature major crops across the EU, to deploy, benchmark, and identify the best configuration of Mobile-net for the classification task, to showcase the possibility of using entropy-based metrics for post-processing of results, and finally to show the applications and limitations of the model in a practical and policy relevant context. In particular, the usefulness of automatically identifying crops on geo-tagged photos is illustrated in the context of the EU's Common Agricultural Policy. The work has produced a dataset of 169,460 images of mature crops for the 12 classes, out of which 15,876 were manually selected as representing a clean sample without any foreign objects or unfavorable conditions. The best performing model achieved a Macro F1 (M-F1) of 0.75 on an imbalanced test dataset of 8,642 photos. Using metrics from information theory, namely - the Equivalence Reference Probability, resulted in achieving an increase of 6%. The most unfavorable conditions for taking such images, across all crop classes, were found to be too early or late in the season. The proposed methodology shows the possibility for using minimal auxiliary data, outside the images themselves, in order to achieve a M-F1 of 0.817 for labelling between 12 major European crops.
Skyline variations allow estimating distance to trees on landscape photos using semantic segmentation
Jan 14, 2022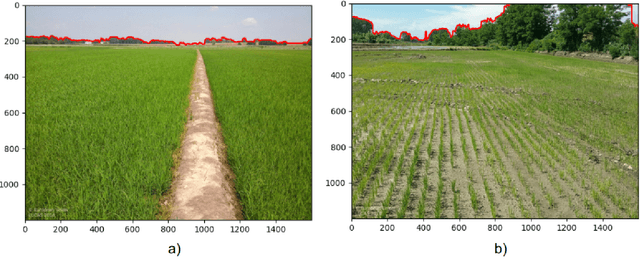
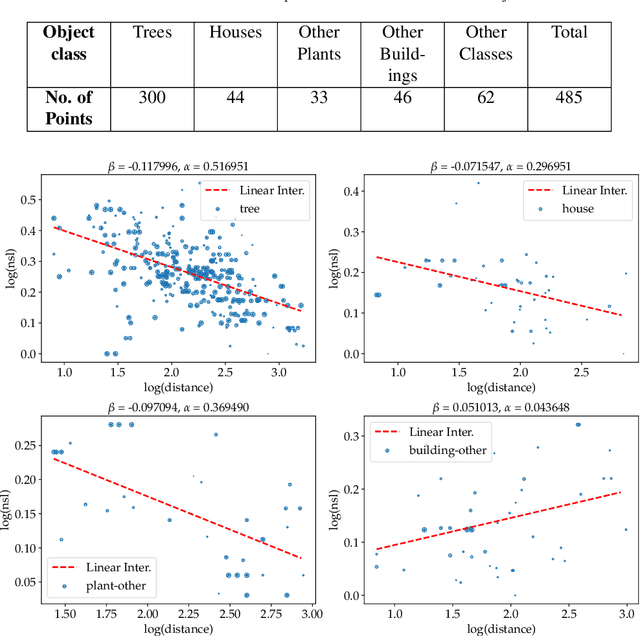
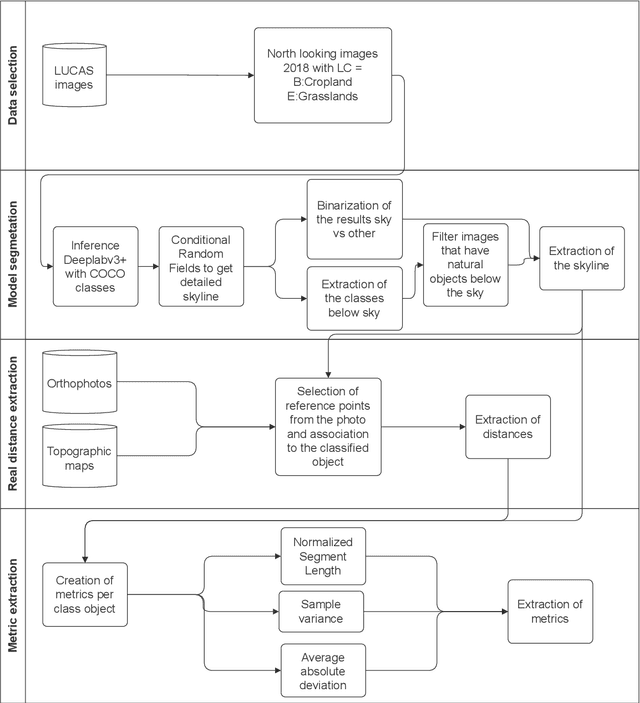

Approximate distance estimation can be used to determine fundamental landscape properties including complexity and openness. We show that variations in the skyline of landscape photos can be used to estimate distances to trees on the horizon. A methodology based on the variations of the skyline has been developed and used to investigate potential relationships with the distance to skyline objects. The skyline signal, defined by the skyline height expressed in pixels, was extracted for several Land Use/Cover Area frame Survey (LUCAS) landscape photos. Photos were semantically segmented with DeepLabV3+ trained with the Common Objects in Context (COCO) dataset. This provided pixel-level classification of the objects forming the skyline. A Conditional Random Fields (CRF) algorithm was also applied to increase the details of the skyline signal. Three metrics, able to capture the skyline signal variations, were then considered for the analysis. These metrics shows a functional relationship with distance for the class of trees, whose contours have a fractal nature. In particular, regression analysis was performed against 475 ortho-photo based distance measurements, and, in the best case, a R2 score equal to 0.47 was achieved. This is an encouraging result which shows the potential of skyline variation metrics for inferring distance related information.
Monitoring crop phenology with street-level imagery using computer vision
Dec 16, 2021
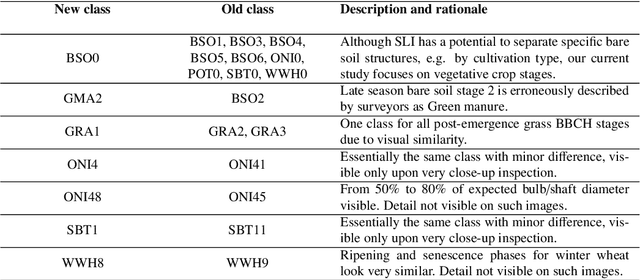


Street-level imagery holds a significant potential to scale-up in-situ data collection. This is enabled by combining the use of cheap high quality cameras with recent advances in deep learning compute solutions to derive relevant thematic information. We present a framework to collect and extract crop type and phenological information from street level imagery using computer vision. During the 2018 growing season, high definition pictures were captured with side-looking action cameras in the Flevoland province of the Netherlands. Each month from March to October, a fixed 200-km route was surveyed collecting one picture per second resulting in a total of 400,000 geo-tagged pictures. At 220 specific parcel locations detailed on the spot crop phenology observations were recorded for 17 crop types. Furthermore, the time span included specific pre-emergence parcel stages, such as differently cultivated bare soil for spring and summer crops as well as post-harvest cultivation practices, e.g. green manuring and catch crops. Classification was done using TensorFlow with a well-known image recognition model, based on transfer learning with convolutional neural networks (MobileNet). A hypertuning methodology was developed to obtain the best performing model among 160 models. This best model was applied on an independent inference set discriminating crop type with a Macro F1 score of 88.1% and main phenological stage at 86.9% at the parcel level. Potential and caveats of the approach along with practical considerations for implementation and improvement are discussed. The proposed framework speeds up high quality in-situ data collection and suggests avenues for massive data collection via automated classification using computer vision.