 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping Knowledge Representations to Concepts: A Review and New Perspectives
Dec 31, 2022The success of neural networks builds to a large extent on their ability to create internal knowledge representations from real-world high-dimensional data, such as images, sound, or text. Approaches to extract and present these representations, in order to explain the neural network's decisions, is an active and multifaceted research field. To gain a deeper understanding of a central aspect of this field, we have performed a targeted review focusing on research that aims to associate internal representations with human understandable concepts. In doing this, we added a perspective on the existing research by using primarily deductive nomological explanations as a proposed taxonomy. We find this taxonomy and theories of causality, useful for understanding what can be expected, and not expected, from neural network explanations. The analysis additionally uncovers an ambiguity in the reviewed literature related to the goal of model explainability; is it understanding the ML model or, is it actionable explanations useful in the deployment domain?
Towards Benchmarking Explainable Artificial Intelligence Methods
Aug 25, 2022
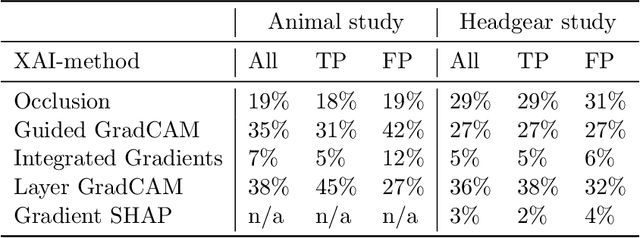


The currently dominating artificial intelligence and machine learning technology, neural networks, builds on inductive statistical learning. Neural networks of today are information processing systems void of understanding and reasoning capabilities, consequently, they cannot explain promoted decisions in a humanly valid form. In this work, we revisit and use fundamental philosophy of science theories as an analytical lens with the goal of revealing, what can be expected, and more importantly, not expected, from methods that aim to explain decisions promoted by a neural network. By conducting a case study we investigate a selection of explainability method's performance over two mundane domains, animals and headgear. Through our study, we lay bare that the usefulness of these methods relies on human domain knowledge and our ability to understand, generalise and reason. The explainability methods can be useful when the goal is to gain further insights into a trained neural network's strengths and weaknesses. If our aim instead is to use these explainability methods to promote actionable decisions or build trust in ML-models they need to be less ambiguous than they are today. In this work, we conclude from our study, that benchmarking explainability methods, is a central quest towards trustworthy artificial intelligence and machine learning.