 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the performance and fragility of large language models on the self-assessment for neurological surgeons
May 29, 2025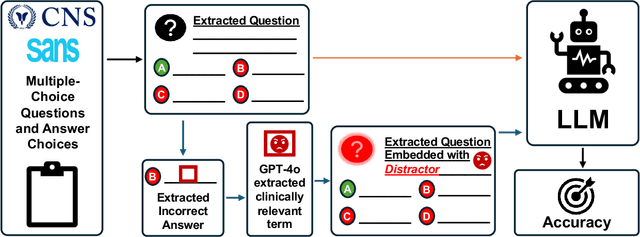
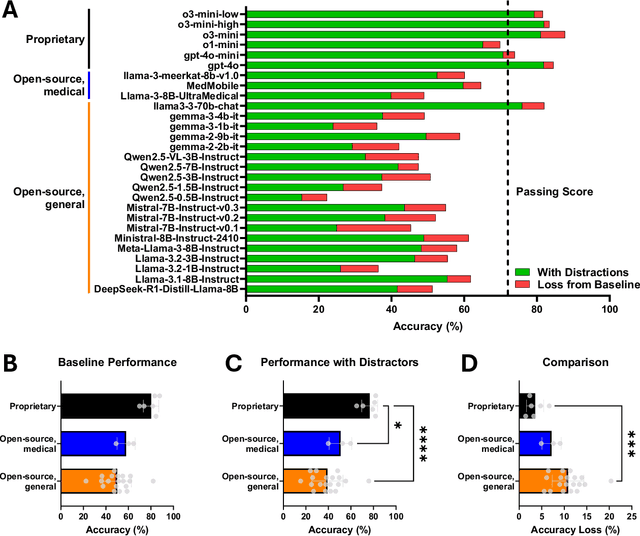
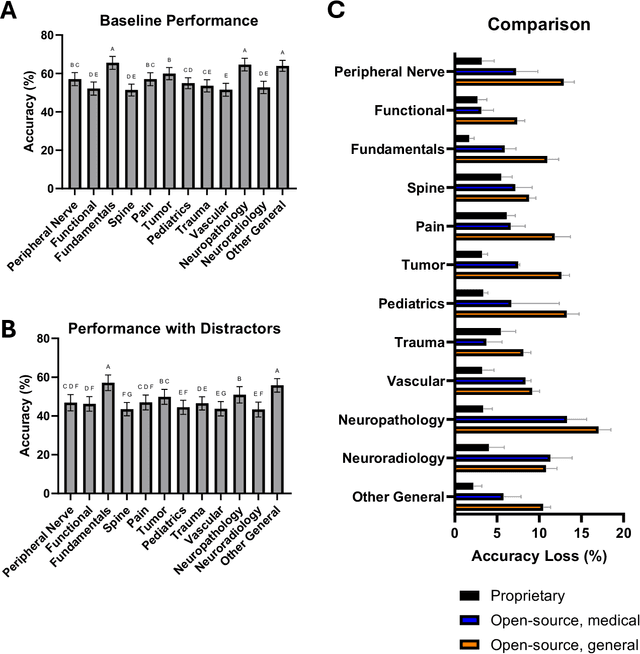
The Congress of Neurological Surgeons Self-Assessment for Neurological Surgeons (CNS-SANS) questions are widely used by neurosurgical residents to prepare for written board examinations. Recently, these questions have also served as benchmarks for evaluating large language models' (LLMs) neurosurgical knowledge. This study aims to assess the performance of state-of-the-art LLMs on neurosurgery board-like questions and to evaluate their robustness to the inclusion of distractor statements. A comprehensive evaluation was conducted using 28 large language models. These models were tested on 2,904 neurosurgery board examination questions derived from the CNS-SANS. Additionally, the study introduced a distraction framework to assess the fragility of these models. The framework incorporated simple, irrelevant distractor statements containing polysemous words with clinical meanings used in non-clinical contexts to determine the extent to which such distractions degrade model performance on standard medical benchmarks. 6 of the 28 tested LLMs achieved board-passing outcomes, with the top-performing models scoring over 15.7% above the passing threshold. When exposed to distractions, accuracy across various model architectures was significantly reduced-by as much as 20.4%-with one model failing that had previously passed. Both general-purpose and medical open-source models experienced greater performance declines compared to proprietary variants when subjected to the added distractors. While current LLMs demonstrate an impressive ability to answer neurosurgery board-like exam questions, their performance is markedly vulnerable to extraneous, distracting information. These findings underscore the critical need for developing novel mitigation strategies aimed at bolstering LLM resilience against in-text distractions, particularly for safe and effective clinical deployment.
Medical large language models are easily distracted
Apr 01, 2025Large language models (LLMs) have the potential to transform medicine, but real-world clinical scenarios contain extraneous information that can hinder performance. The rise of assistive technologies like ambient dictation, which automatically generates draft notes from live patient encounters, has the potential to introduce additional noise making it crucial to assess the ability of LLM's to filter relevant data. To investigate this, we developed MedDistractQA, a benchmark using USMLE-style questions embedded with simulated real-world distractions. Our findings show that distracting statements (polysemous words with clinical meanings used in a non-clinical context or references to unrelated health conditions) can reduce LLM accuracy by up to 17.9%. Commonly proposed solutions to improve model performance such as retrieval-augmented generation (RAG) and medical fine-tuning did not change this effect and in some cases introduced their own confounders and further degraded performance. Our findings suggest that LLMs natively lack the logical mechanisms necessary to distinguish relevant from irrelevant clinical information, posing challenges for real-world applications. MedDistractQA and our results highlights the need for robust mitigation strategies to enhance LLM resilience to extraneous information.
MedMobile: A mobile-sized language model with expert-level clinical capabilities
Oct 11, 2024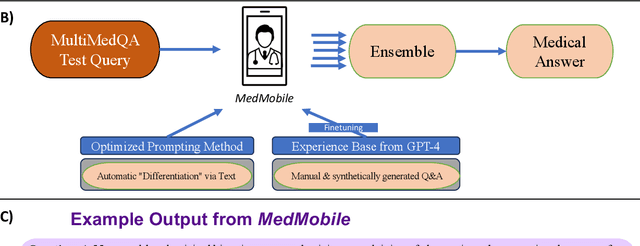

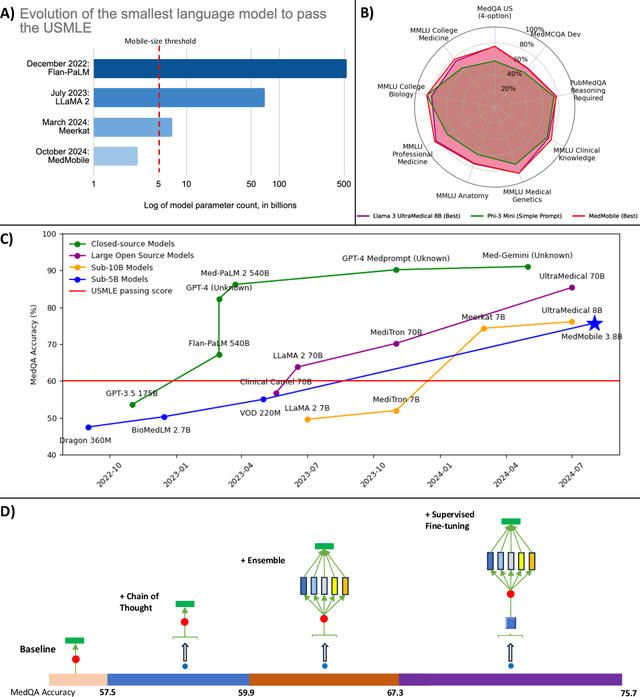
Language models (LMs) have demonstrated expert-level reasoning and recall abilities in medicine. However, computational costs and privacy concerns are mounting barriers to wide-scale implementation. We introduce a parsimonious adaptation of phi-3-mini, MedMobile, a 3.8 billion parameter LM capable of running on a mobile device, for medical applications. We demonstrate that MedMobile scores 75.7% on the MedQA (USMLE), surpassing the passing mark for physicians (~60%), and approaching the scores of models 100 times its size. We subsequently perform a careful set of ablations, and demonstrate that chain of thought, ensembling, and fine-tuning lead to the greatest performance gains, while unexpectedly retrieval augmented generation fails to demonstrate significant improvements