 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepPFCN: Deep Parallel Feature Consensus Network For Person Re-Identification
Nov 18, 2019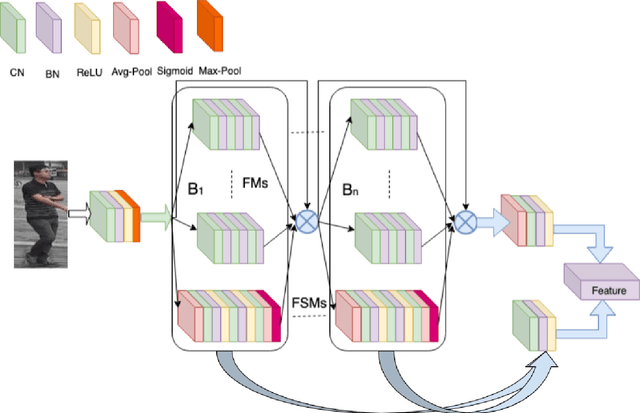
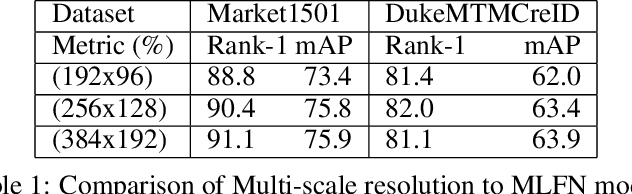
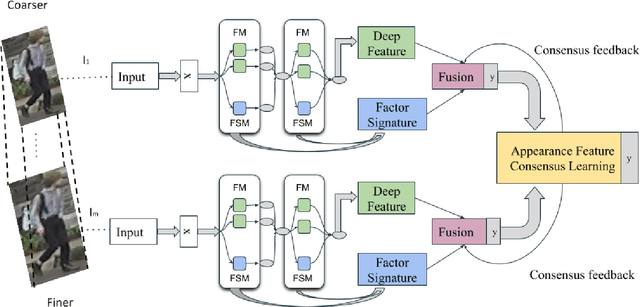
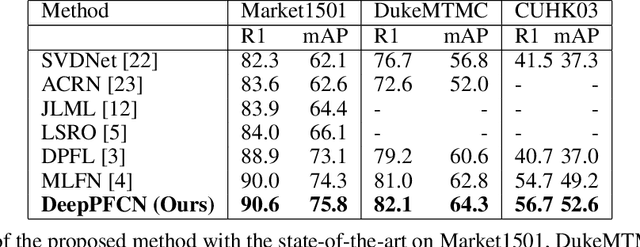
Person re-identification aims to associate images of the same person over multiple non-overlapping camera views at different times. Depending on the human operator, manual re-identification in large camera networks is highly time consuming and erroneous. Automated person re-identification is required due to the extensive quantity of visual data produced by rapid inflation of large scale distributed multi-camera systems. The state-of-the-art works focus on learning and factorize person appearance features into latent discriminative factors at multiple semantic levels. We propose Deep Parallel Feature Consensus Network (DeepPFCN), a novel network architecture that learns multi-scale person appearance features using convolutional neural networks. This model factorizes the visual appearance of a person into latent discriminative factors at multiple semantic levels. Finally consensus is built. The feature representations learned by DeepPFCN are more robust for the person re-identification task, as we learn discriminative scale-specific features and maximize multi-scale feature fusion selections in multi-scale image inputs. We further exploit average and max pooling in separate scale for person-specific task to discriminate features globally and locally. We demonstrate the re-identification advantages of the proposed DeepPFCN model over the state-of-the-art re-identification methods on three benchmark datasets: Market1501, DukeMTMCreID, and CUHK03. We have achieved mAP results of 75.8%, 64.3%, and 52.6% respectively on these benchmark datasets.
Facial Expression Recognition using Visual Saliency and Deep Learning
Aug 26, 2017
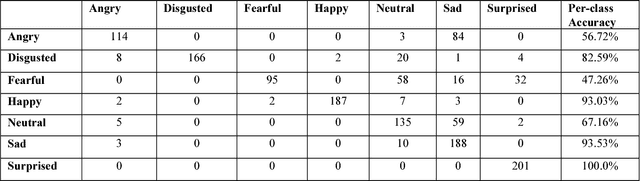
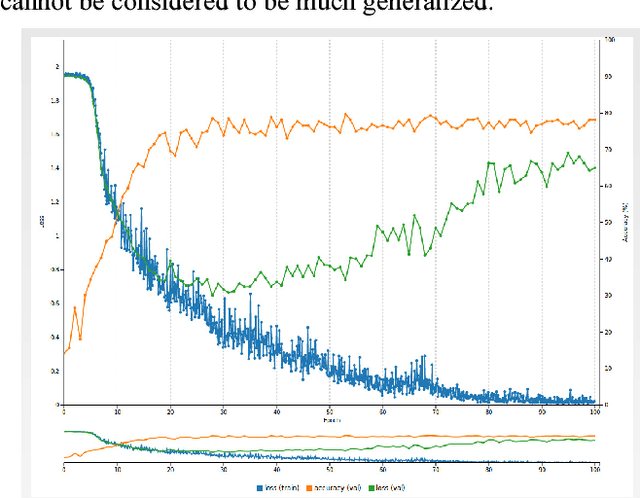
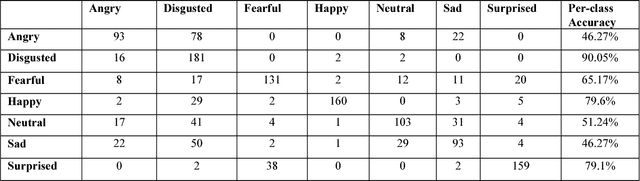
We have developed a convolutional neural network for the purpose of recognizing facial expressions in human beings. We have fine-tuned the existing convolutional neural network model trained on the visual recognition dataset used in the ILSVRC2012 to two widely used facial expression datasets - CFEE and RaFD, which when trained and tested independently yielded test accuracies of 74.79% and 95.71%, respectively. Generalization of results was evident by training on one dataset and testing on the other. Further, the image product of the cropped faces and their visual saliency maps were computed using Deep Multi-Layer Network for saliency prediction and were fed to the facial expression recognition CNN. In the most generalized experiment, we observed the top-1 accuracy in the test set to be 65.39%. General confusion trends between different facial expressions as exhibited by humans were also observed.