 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Learning for Multi-User CSI Feedback
Dec 01, 2022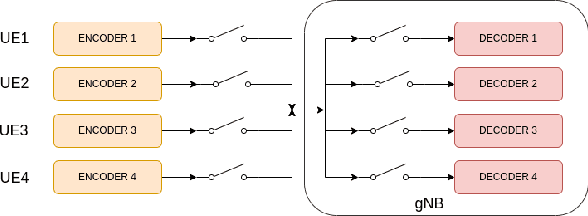
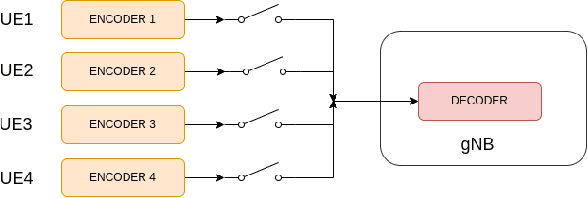

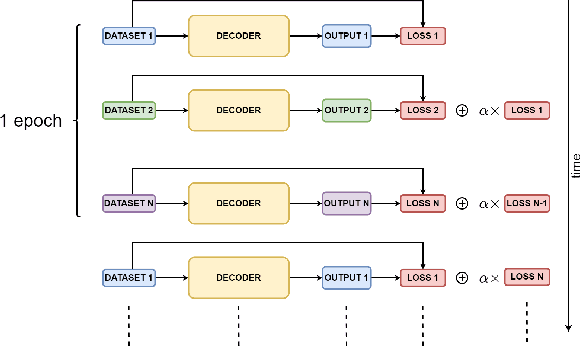
Deep learning-based massive MIMO CSI feedback has received a lot of attention in recent years. Now, there exists a plethora of CSI feedback models mostly based on auto-encoders (AE) architecture with an encoder network at the user equipment (UE) and a decoder network at the gNB (base station). However, these models are trained for a single user in a single-channel scenario, making them ineffective in multi-user scenarios with varying channels and varying encoder models across the users. In this work, we address this problem by exploiting the techniques of multi-task learning (MTL) in the context of massive MIMO CSI feedback. In particular, we propose methods to jointly train the existing models in a multi-user setting while increasing the performance of some of the constituent models. For example, through our proposed methods, CSINet when trained along with STNet has seen a $39\%$ increase in performance while increasing the sum rate of the system by $0.07bps/Hz$.
A Spatially Separable Attention Mechanism for massive MIMO CSI Feedback
Aug 05, 2022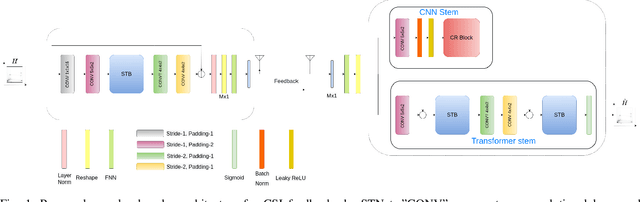
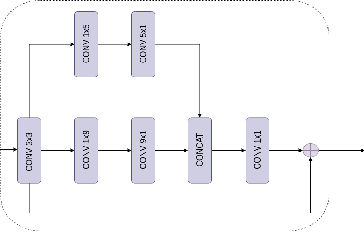
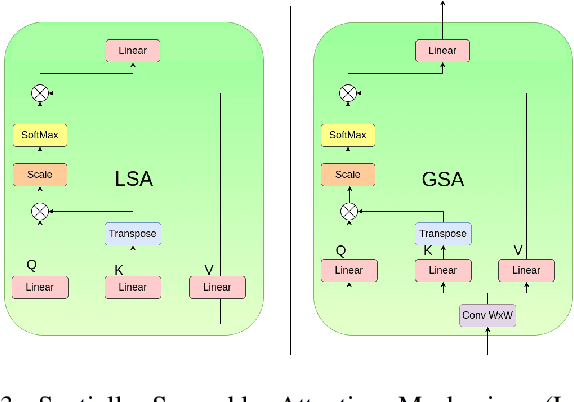
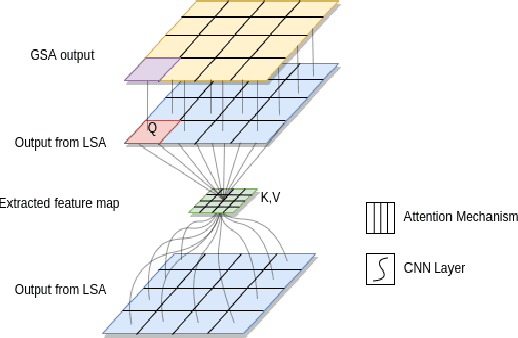
Channel State Information (CSI) Feedback plays a crucial role in achieving higher gains through beamforming. However, for a massive MIMO system, this feedback overhead is huge and grows linearly with the number of antennas. To reduce the feedback overhead several compressive sensing (CS) techniques were implemented in recent years but these techniques are often iterative and are computationally complex to realize in power-constrained user equipment (UE). Hence, a data-based deep learning approach took over in these recent years introducing a variety of neural networks for CSI compression. Specifically, transformer-based networks have been shown to achieve state-of-the-art performance. However, the multi-head attention operation, which is at the core of transformers, is computationally complex making transformers difficult to implement on a UE. In this work, we present a lightweight transformer named STNet which uses a spatially separable attention mechanism that is significantly less complex than the traditional full-attention. Equipped with this, STNet outperformed state-of-the-art models in some scenarios with approximately $1/10^{th}$ of the resources.