 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation for BERT Unsupervised Domain Adaptation
Oct 23, 2020
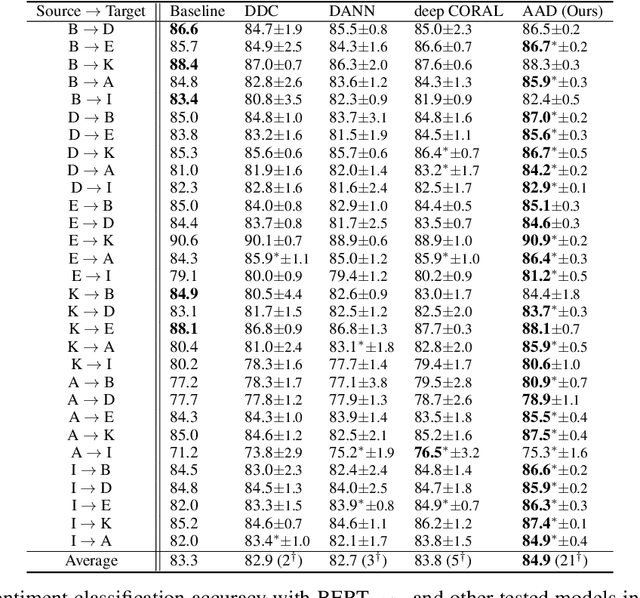


A pre-trained language model, BERT, has brought significant performance improvements across a range of natural language processing tasks. Since the model is trained on a large corpus of diverse topics, it shows robust performance for domain shift problems in which data distributions at training (source data) and testing (target data) differ while sharing similarities. Despite its great improvements compared to previous models, it still suffers from performance degradation due to domain shifts. To mitigate such problems, we propose a simple but effective unsupervised domain adaptation method, adversarial adaptation with distillation (AAD), which combines the adversarial discriminative domain adaptation (ADDA) framework with knowledge distillation. We evaluate our approach in the task of cross-domain sentiment classification on 30 domain pairs, advancing the state-of-the-art performance for unsupervised domain adaptation in text sentiment classification.