 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparsity based morphological identification of heartbeats
Jan 16, 2023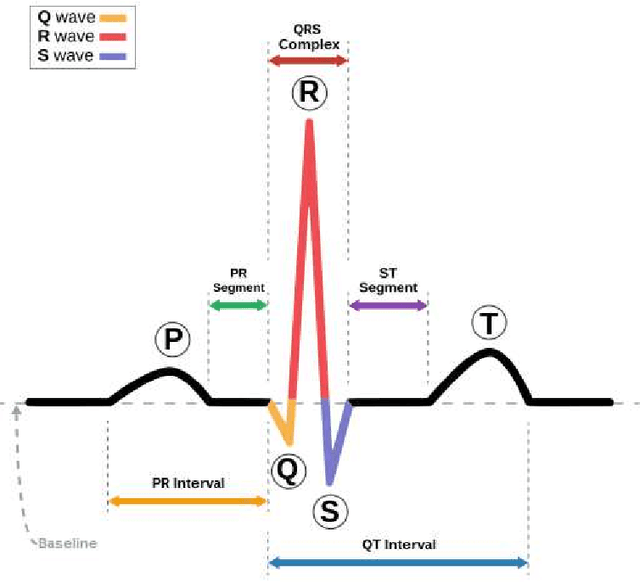

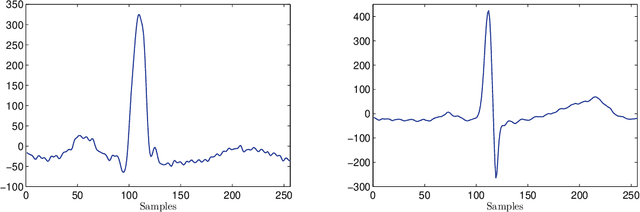

The electrocardiogram (ECG) is one of the most common primary tests to evaluate the health of the heart. Reliable automatic interpretation of ECG records is crucial to the goal of improving public health. It can enable a safe inexpensive monitoring. This work presents a new methodology for morphological identification of heartbeats, which is placed outside the usual machine learning framework. The proposal considers the sparsity of the representation of a heartbeat as a parameter for morphological identification. The approach involves greedy algorithms for selecting elements from redundant dictionaries, which should be previously learnt from examples of the classes to be identified. Using different metrics of sparsity, the dictionary rendering the smallest sparsity value, for the equivalent approximation quality of a new heartbeat, classifies the morphology of that beat. This study focuses on a procedure of learning the dictionaries for representing heartbeats and compares several metrics of sparsity for morphological identification on the basis of those metrics. The suitability of the method is illustrated by binary differentiation of Normal and Ventricular heartbeats in the MIT-BIH Arrhythmia data set. In general classification 99.7% of the Normal beats and 97.6% of the Ventricular beats in the testing sets are correctly identified. In interpatient assessment 91.8% of the Normal beats and 91.0% of Ventricular beats are correctly identified. Even more important than these scores is the fact that they are produced on the bases of a single parameter. The numerical tests, designed to emphasise the interpretability and reliability of the approach, demonstrate the potential of the method to contribute towards the development of a well grounded expert system for classification of heartbeats in ECG records.