 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEcho State Networks for Reinforcement Learning
Feb 11, 2021

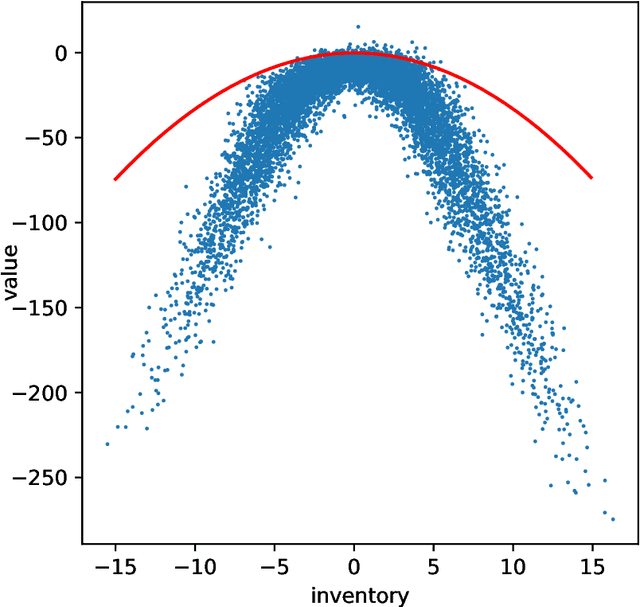
Echo State Networks (ESNs) are a type of single-layer recurrent neural network with randomly-chosen internal weights and a trainable output layer. We prove under mild conditions that a sufficiently large Echo State Network (ESN) can approximate the value function of a broad class of stochastic and deterministic control problems. Such control problems are generally non-Markovian. We describe how the ESN can form the basis for novel (and computationally efficient) reinforcement learning algorithms in a non-Markovian framework. We demonstrate this theory with two examples. In the first, we use an ESN to solve a deterministic, partially observed, control problem which is a simple game we call `Bee World'. In the second example, we consider a stochastic control problem inspired by a market making problem in mathematical finance. In both cases we can compare the dynamics of the algorithms with analytic solutions to show that even after only a single reinforcement policy iteration the algorithms perform with reasonable skill.