 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenBreak: Bypassing Text Classification Models Through Token Manipulation
Jun 09, 2025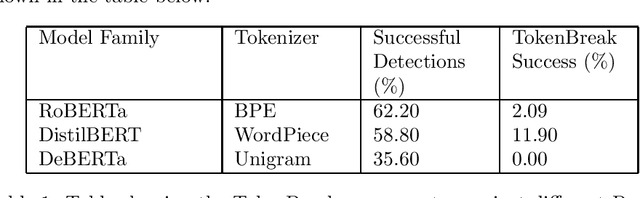


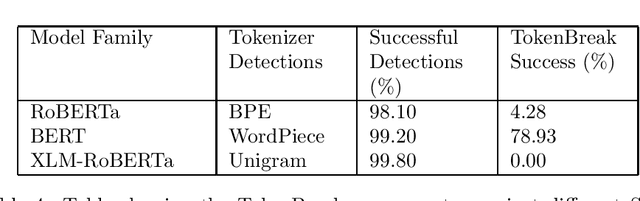
Natural Language Processing (NLP) models are used for text-related tasks such as classification and generation. To complete these tasks, input data is first tokenized from human-readable text into a format the model can understand, enabling it to make inferences and understand context. Text classification models can be implemented to guard against threats such as prompt injection attacks against Large Language Models (LLMs), toxic input and cybersecurity risks such as spam emails. In this paper, we introduce TokenBreak: a novel attack that can bypass these protection models by taking advantage of the tokenization strategy they use. This attack technique manipulates input text in such a way that certain models give an incorrect classification. Importantly, the end target (LLM or email recipient) can still understand and respond to the manipulated text and therefore be vulnerable to the very attack the protection model was put in place to prevent. The tokenizer is tied to model architecture, meaning it is possible to predict whether or not a model is vulnerable to attack based on family. We also present a defensive strategy as an added layer of protection that can be implemented without having to retrain the defensive model.
Knowledge Return Oriented Prompting (KROP)
Jun 11, 2024



Many Large Language Models (LLMs) and LLM-powered apps deployed today use some form of prompt filter or alignment to protect their integrity. However, these measures aren't foolproof. This paper introduces KROP, a prompt injection technique capable of obfuscating prompt injection attacks, rendering them virtually undetectable to most of these security measures.