 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Explainability for Plant Disease Classification with Disentangled Variational Autoencoders
Feb 08, 2021
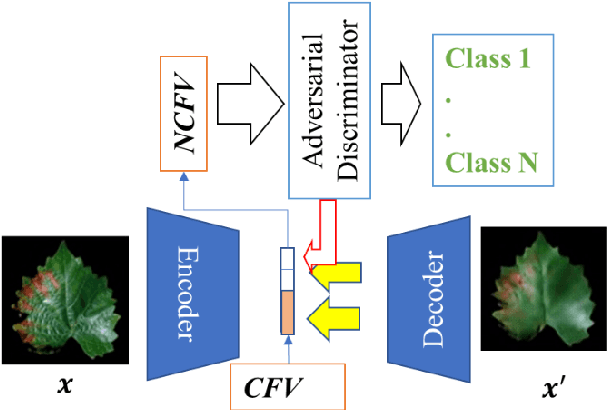


Agricultural image recognition tasks are becoming increasingly dependent on deep learning (DL). Despite its excellent performance, it is difficult to comprehend what type of logic or features DL uses in its decision making. This has become a roadblock for the implementation and development of DL-based image recognition methods because knowing the logic or features used in decision making, such as in a classification task, is very important for verification, algorithm improvement, training data improvement, knowledge extraction, etc. To mitigate such problems, we developed a classification method based on a variational autoencoder architecture that can show not only the location of the most important features but also what variations of that particular feature are used. Using the PlantVillage dataset, we achieved an acceptable level of explainability without sacrificing the accuracy of the classification. Although the proposed method was tested for disease diagnosis in some crops, the method can be extended to other crops as well as other image classification tasks. In the future, we hope to use this explainable artificial intelligence algorithm in disease identification tasks, such as the identification of potato blackleg disease and potato virus Y (PVY), and other image classification tasks.
Stochastic Threshold Model Trees: A Tree-Based Ensemble Method for Dealing with Extrapolation
Sep 19, 2020



In the field of chemistry, there have been many attempts to predict the properties of unknown compounds from statistical models constructed using machine learning. In an area where many known compounds are present (the interpolation area), an accurate model can be constructed. In contrast, data in areas where there are no known compounds (the extrapolation area) are generally difficult to predict. However, in the development of new materials, it is desirable to search this extrapolation area and discover compounds with unprecedented physical properties. In this paper, we propose Stochastic Threshold Model Trees (STMT), an extrapolation method that reflects the trend of the data, while maintaining the accuracy of conventional interpolation methods. The behavior of STMT is confirmed through experiments using both artificial and real data. In the case of the real data, although there is no significant overall improvement in accuracy, there is one compound for which the prediction accuracy is notably improved, suggesting that STMT reflects the data trends in the extrapolation area. We believe that the proposed method will contribute to more efficient searches in situations such as new material development.