 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale moral machine experiment on large language models
Nov 11, 2024The rapid advancement of Large Language Models (LLMs) and their potential integration into autonomous driving systems necessitates understanding their moral decision-making capabilities. While our previous study examined four prominent LLMs using the Moral Machine experimental framework, the dynamic landscape of LLM development demands a more comprehensive analysis. Here, we evaluate moral judgments across 51 different LLMs, including multiple versions of proprietary models (GPT, Claude, Gemini) and open-source alternatives (Llama, Gemma), to assess their alignment with human moral preferences in autonomous driving scenarios. Using a conjoint analysis framework, we evaluated how closely LLM responses aligned with human preferences in ethical dilemmas and examined the effects of model size, updates, and architecture. Results showed that proprietary models and open-source models exceeding 10 billion parameters demonstrated relatively close alignment with human judgments, with a significant negative correlation between model size and distance from human judgments in open-source models. However, model updates did not consistently improve alignment with human preferences, and many LLMs showed excessive emphasis on specific ethical principles. These findings suggest that while increasing model size may naturally lead to more human-like moral judgments, practical implementation in autonomous driving systems requires careful consideration of the trade-off between judgment quality and computational efficiency. Our comprehensive analysis provides crucial insights for the ethical design of autonomous systems and highlights the importance of considering cultural contexts in AI moral decision-making.
All in How You Ask for It: Simple Black-Box Method for Jailbreak Attacks
Jan 22, 2024Large Language Models (LLMs) like ChatGPT face `jailbreak' challenges, where safeguards are bypassed to produce ethically harmful prompts. This study proposes a simple black-box method to effectively generate jailbreak prompts, overcoming the high complexity and computational costs associated with existing methods. The proposed technique iteratively rewrites harmful prompts into non-harmful expressions using the target LLM itself, based on the hypothesis that LLMs can directly sample expressions that bypass safeguards. Demonstrated through experiments with ChatGPT (GPT-3.5 and GPT-4) and Gemini-Pro, this method achieved an attack success rate of over 80% within an average of 5 iterations and remained effective despite model updates. The generated jailbreak prompts were naturally-worded and concise; moreover, they were difficult-to-defend. These results indicate that creating effective jailbreak prompts is simpler than previously considered, suggesting that black-box jailbreak attacks pose a more serious threat.
The Moral Machine Experiment on Large Language Models
Sep 12, 2023As large language models (LLMs) become more deeply integrated into various sectors, understanding how they make moral judgments has become crucial, particularly in the realm of autonomous driving. This study utilized the Moral Machine framework to investigate the ethical decision-making tendencies of prominent LLMs, including GPT-3.5, GPT-4, PaLM 2, and Llama 2, comparing their responses to human preferences. While LLMs' and humans' preferences such as prioritizing humans over pets and favoring saving more lives are broadly aligned, PaLM 2 and Llama 2, especially, evidence distinct deviations. Additionally, despite the qualitative similarities between the LLM and human preferences, there are significant quantitative disparities, suggesting that LLMs might lean toward more uncompromising decisions, compared to the milder inclinations of humans. These insights elucidate the ethical frameworks of LLMs and their potential implications for autonomous driving.
Simple black-box universal adversarial attacks on medical image classification based on deep neural networks
Aug 11, 2021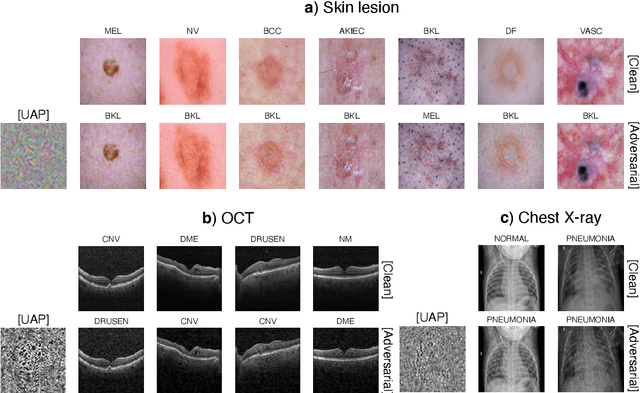
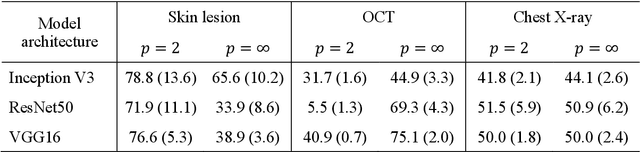
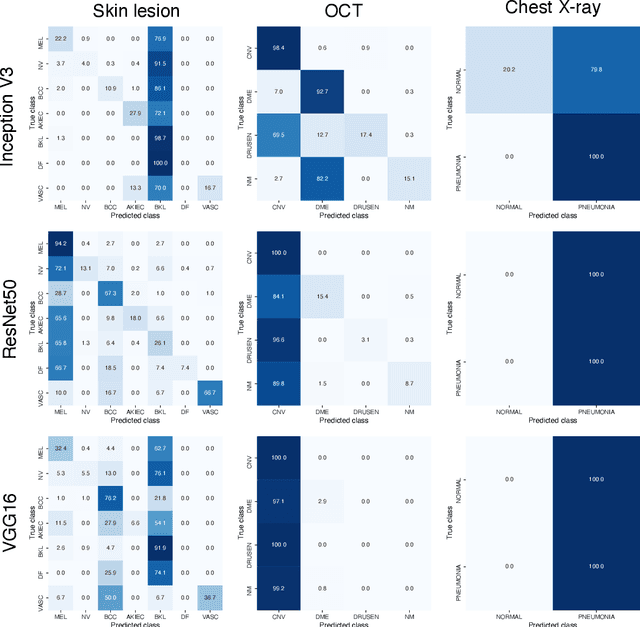
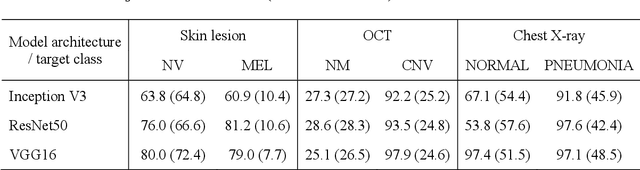
Universal adversarial attacks, which hinder most deep neural network (DNN) tasks using only a small single perturbation called a universal adversarial perturbation (UAP), is a realistic security threat to the practical application of a DNN. In particular, such attacks cause serious problems in medical imaging. Given that computer-based systems are generally operated under a black-box condition in which only queries on inputs are allowed and outputs are accessible, the impact of UAPs seems to be limited because well-used algorithms for generating UAPs are limited to a white-box condition in which adversaries can access the model weights and loss gradients. Nevertheless, we demonstrate that UAPs are easily generatable using a relatively small dataset under black-box conditions. In particular, we propose a method for generating UAPs using a simple hill-climbing search based only on DNN outputs and demonstrate the validity of the proposed method using representative DNN-based medical image classifications. Black-box UAPs can be used to conduct both non-targeted and targeted attacks. Overall, the black-box UAPs showed high attack success rates (40% to 90%), although some of them had relatively low success rates because the method only utilizes limited information to generate UAPs. The vulnerability of black-box UAPs was observed in several model architectures. The results indicate that adversaries can also generate UAPs through a simple procedure under the black-box condition to foil or control DNN-based medical image diagnoses, and that UAPs are a more realistic security threat.
Vulnerability of deep neural networks for detecting COVID-19 cases from chest X-ray images to universal adversarial attacks
May 22, 2020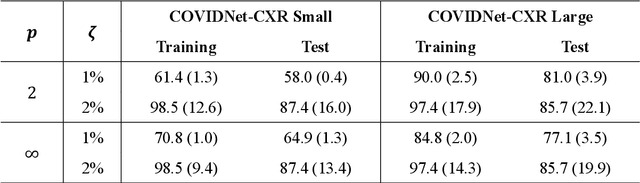
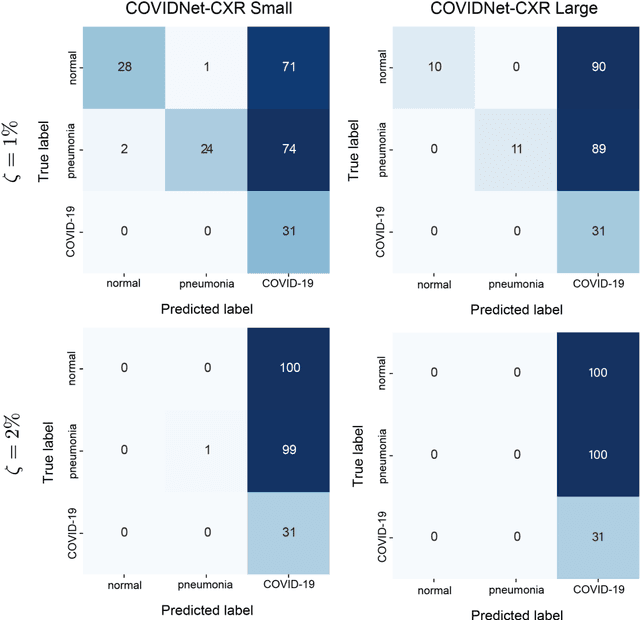
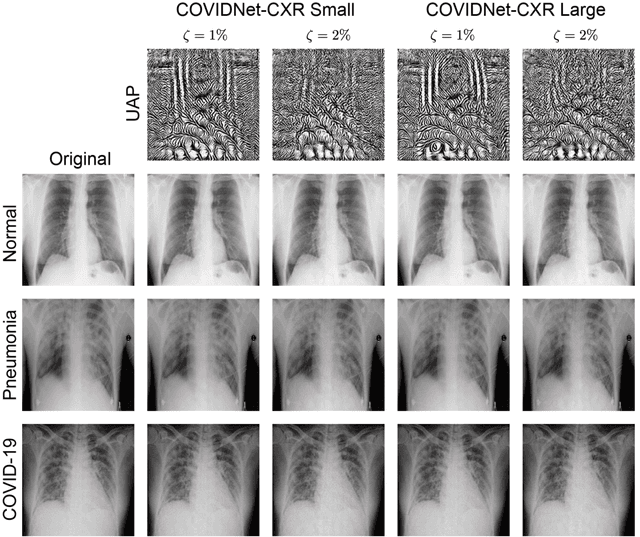
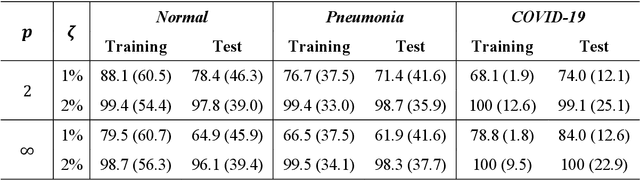
Under the epidemic of the novel coronavirus disease 2019 (COVID-19), chest X-ray computed tomography imaging is being used for effectively screening COVID-19 patients. The development of computer-aided systems based on deep neural networks (DNNs) has been advanced, to rapidly and accurately detect COVID-19 cases, because the need for expert radiologists, who are limited in number, forms a bottleneck for the screening. However, so far, the vulnerability of DNN-based systems has been poorly evaluated, although DNNs are vulnerable to a single perturbation, called universal adversarial perturbation (UAP), which can induce DNN failure in most classification tasks. Thus, we focus on representative DNN models for detecting COVID-19 cases from chest X-ray images and evaluate their vulnerability to UAPs generated using simple iterative algorithms. We consider nontargeted UAPs, which cause a task failure resulting in an input being assigned an incorrect label, and targeted UAPs, which cause the DNN to classify an input into a specific class. The results demonstrate that the models are vulnerable to nontargeted and targeted UAPs, even in case of small UAPs. In particular, 2% norm of the UPAs to the average norm of an image in the image dataset achieves >85% and >90% success rates for the nontargeted and targeted attacks, respectively. Due to the nontargeted UAPs, the DNN models judge most chest X-ray images as COVID-19 cases. The targeted UAPs make the DNN models classify most chest X-ray images into a given target class. The results indicate that careful consideration is required in practical applications of DNNs to COVID-19 diagnosis; in particular, they emphasize the need for strategies to address security concerns. As an example, we show that iterative fine-tuning of the DNN models using UAPs improves the robustness of the DNN models against UAPs.
Simple iterative method for generating targeted universal adversarial perturbations
Nov 18, 2019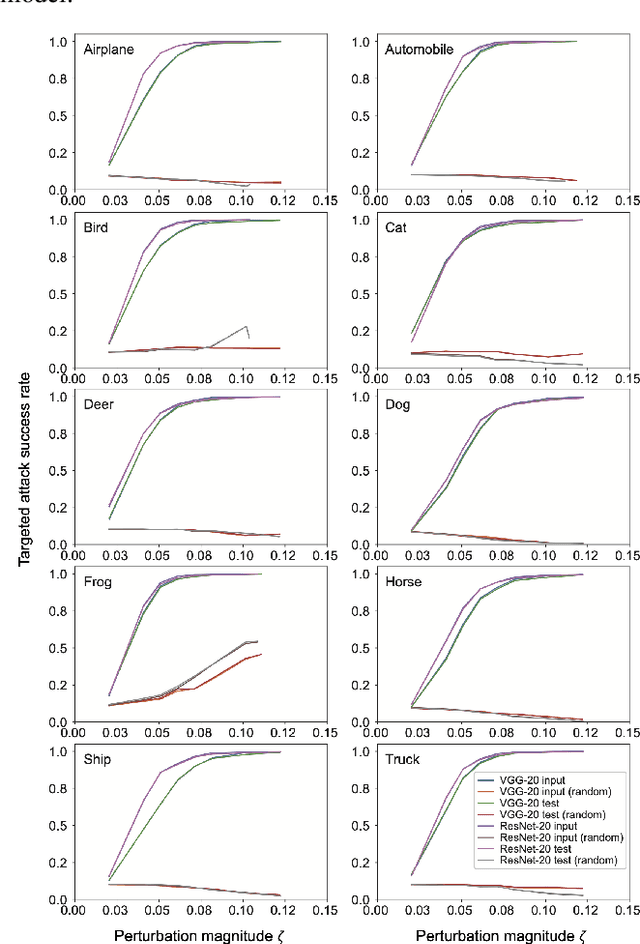

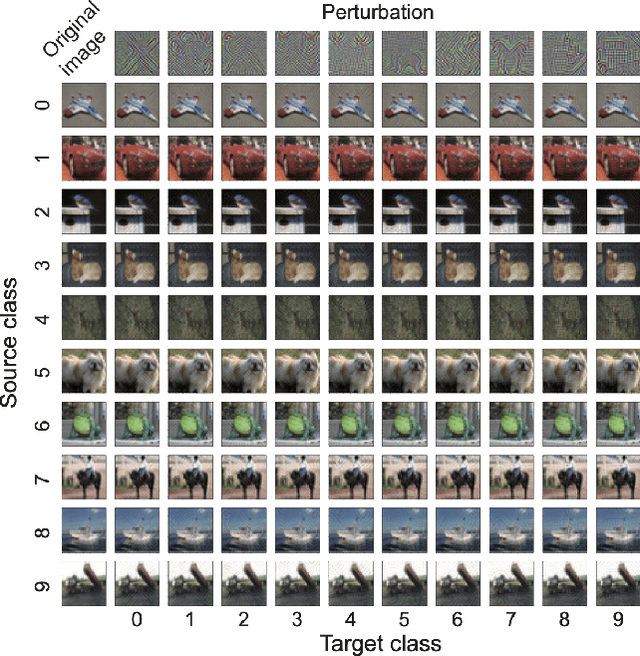

Deep neural networks (DNNs) are vulnerable to adversarial attacks. In particular, a single perturbation known as the universal adversarial perturbation (UAP) can foil most classification tasks conducted by DNNs. Thus, different methods for generating UAPs are required to fully evaluate the vulnerability of DNNs. A realistic evaluation would be with cases that consider targeted attacks; wherein the generated UAP causes DNN to classify an input into a specific class. However, the development of UAPs for targeted attacks has largely fallen behind that of UAPs for non-targeted attacks. Therefore, we propose a simple iterative method to generate UAPs for targeted attacks. Our method combines the simple iterative method for generating non-targeted UAPs and the fast gradient sign method for generating a targeted adversarial perturbation for an input. We applied the proposed method to state-of-the-art DNN models for image classification and proved the existence of almost imperceptible UAPs for targeted attacks; further, we demonstrated that such UAPs are easily generatable.