 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced document retrieval with topic embeddings
Aug 19, 2024



Document retrieval systems have experienced a revitalized interest with the advent of retrieval-augmented generation (RAG). RAG architecture offers a lower hallucination rate than LLM-only applications. However, the accuracy of the retrieval mechanism is known to be a bottleneck in the efficiency of these applications. A particular case of subpar retrieval performance is observed in situations where multiple documents from several different but related topics are in the corpus. We have devised a new vectorization method that takes into account the topic information of the document. The paper introduces this new method for text vectorization and evaluates it in the context of RAG. Furthermore, we discuss the challenge of evaluating RAG systems, which pertains to the case at hand.
Open foundation models for Azerbaijani language
Jul 02, 2024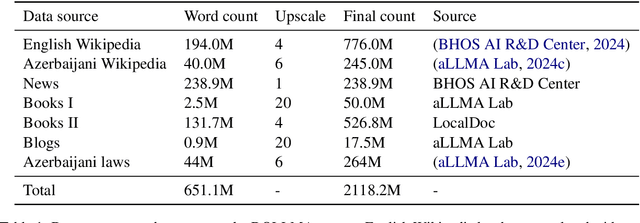
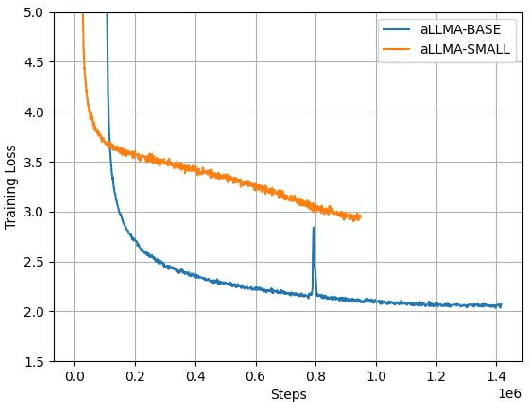

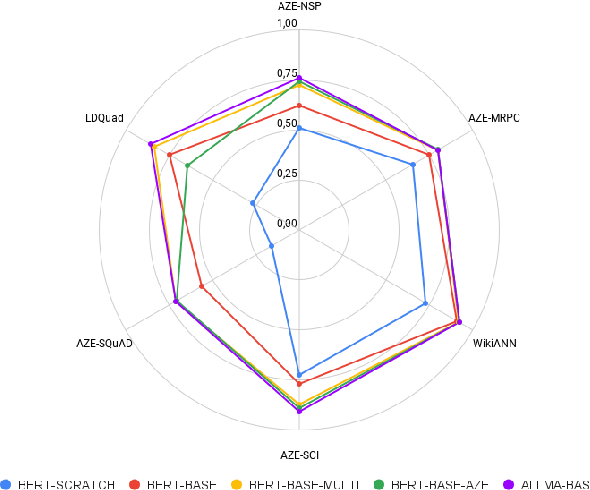
The emergence of multilingual large language models has enabled the development of language understanding and generation systems in Azerbaijani. However, most of the production-grade systems rely on cloud solutions, such as GPT-4. While there have been several attempts to develop open foundation models for Azerbaijani, these works have not found their way into common use due to a lack of systemic benchmarking. This paper encompasses several lines of work that promote open-source foundation models for Azerbaijani. We introduce (1) a large text corpus for Azerbaijani, (2) a family of encoder-only language models trained on this dataset, (3) labeled datasets for evaluating these models, and (4) extensive evaluation that covers all major open-source models with Azerbaijani support.