 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomino Saliency Metrics: Improving Existing Channel Saliency Metrics with Structural Information
May 04, 2022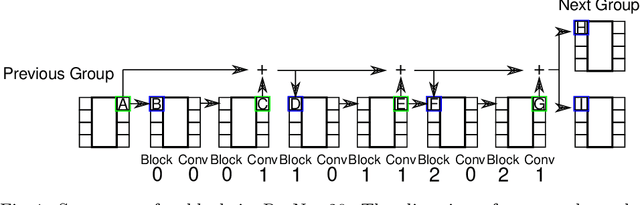
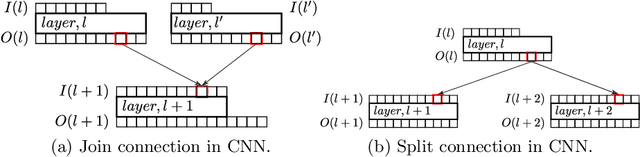
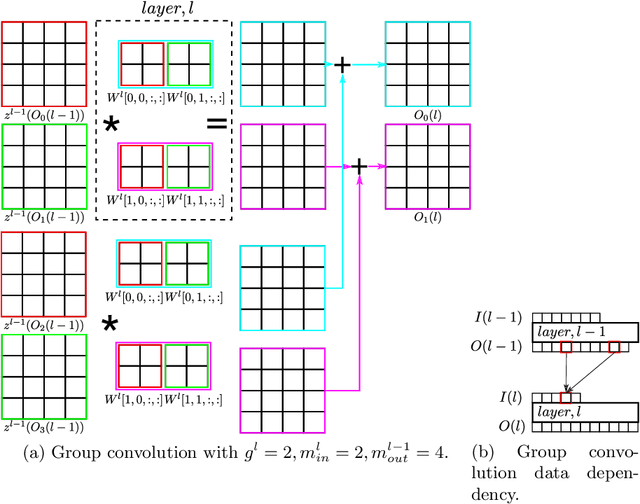
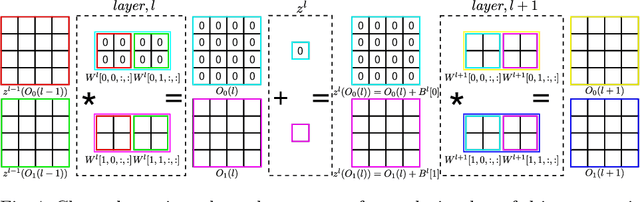
Channel pruning is used to reduce the number of weights in a Convolutional Neural Network (CNN). Channel pruning removes slices of the weight tensor so that the convolution layer remains dense. The removal of these weight slices from a single layer causes mismatching number of feature maps between layers of the network. A simple solution is to force the number of feature map between layers to match through the removal of weight slices from subsequent layers. This additional constraint becomes more apparent in DNNs with branches where multiple channels need to be pruned together to keep the network dense. Popular pruning saliency metrics do not factor in the structural dependencies that arise in DNNs with branches. We propose Domino metrics (built on existing channel saliency metrics) to reflect these structural constraints. We test Domino saliency metrics against the baseline channel saliency metrics on multiple networks with branches. Domino saliency metrics improved pruning rates in most tested networks and up to 25% in AlexNet on CIFAR-10.
Composition of Saliency Metrics for Channel Pruning with a Myopic Oracle
Apr 03, 2020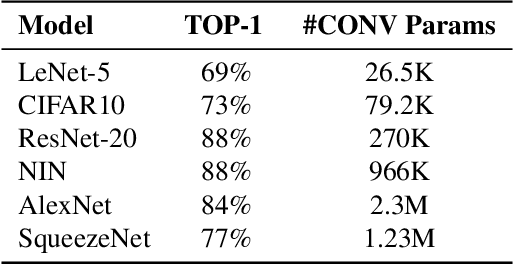
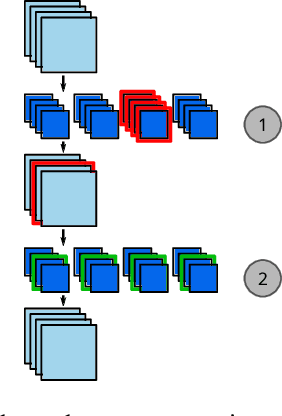

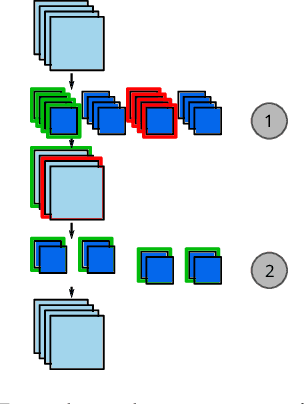
The computation and memory needed for Convolutional Neural Network (CNN) inference can be reduced by pruning weights from the trained network. Pruning is guided by a pruning saliency, which heuristically approximates the change in the loss function associated with the removal of specific weights. Many pruning signals have been proposed, but the performance of each heuristic depends on the particular trained network. This leaves the data scientist with a difficult choice. When using any one saliency metric for the entire pruning process, we run the risk of the metric assumptions being invalidated, leading to poor decisions being made by the metric. Ideally we could combine the best aspects of different saliency metrics. However, despite an extensive literature review, we are unable to find any prior work on composing different saliency metrics. The chief difficulty lies in combining the numerical output of different saliency metrics, which are not directly comparable. We propose a method to compose several primitive pruning saliencies, to exploit the cases where each saliency measure does well. Our experiments show that the composition of saliencies avoids many poor pruning choices identified by individual saliencies. In most cases our method finds better selections than even the best individual pruning saliency.
A Taxonomy of Channel Pruning Signals in CNNs
Jun 11, 2019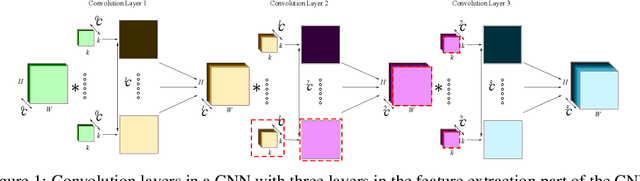


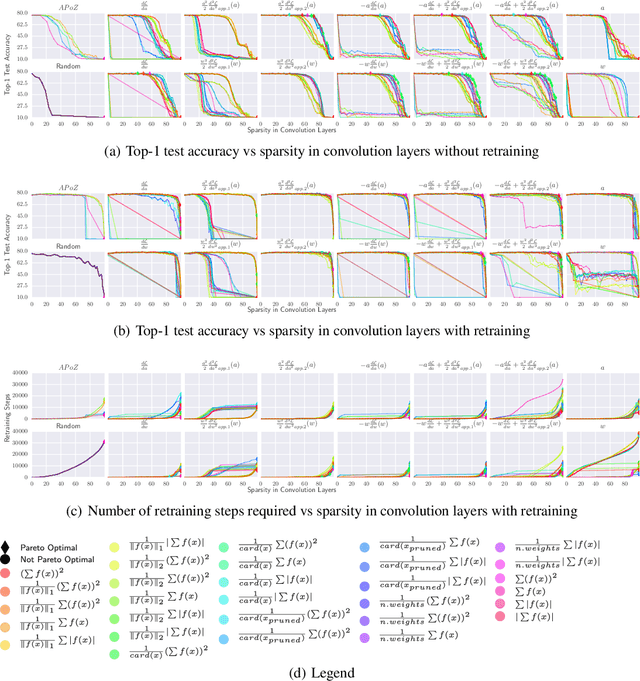
Convolutional neural networks (CNNs) are widely used for classification problems. However, they often require large amounts of computation and memory which are not readily available in resource constrained systems. Pruning unimportant parameters from CNNs to reduce these requirements has been a subject of intensive research in recent years. However, novel approaches in pruning signals are sometimes difficult to compare against each other. We propose a taxonomy that classifies pruning signals based on four mostly-orthogonal components of the signal. We also empirically evaluate 396 pruning signals including existing ones, and new signals constructed from the components of existing signals. We find that some of our newly constructed signals outperform the best existing pruning signals.