 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Coreset Constructions for the Fuzzy $K$-Means Problem
Sep 27, 2018The fuzzy $K$-means problem is a popular generalization of the well-known $K$-means problem to soft clusterings. We present the first coresets for fuzzy $K$-means with size linear in the dimension, polynomial in the number of clusters, and poly-logarithmic in the number of points. We show that these coresets can be employed in the computation of a $(1+\epsilon)$-approximation for fuzzy $K$-means, improving previously presented results. We further show that our coresets can be maintained in an insertion-only streaming setting, where data points arrive one-by-one.
Adaptive Seeding for Gaussian Mixture Models
May 30, 2017



We present new initialization methods for the expectation-maximization algorithm for multivariate Gaussian mixture models. Our methods are adaptions of the well-known $K$-means++ initialization and the Gonzalez algorithm. Thereby we aim to close the gap between simple random, e.g. uniform, and complex methods, that crucially depend on the right choice of hyperparameters. Our extensive experiments indicate the usefulness of our methods compared to common techniques and methods, which e.g. apply the original $K$-means++ and Gonzalez directly, with respect to artificial as well as real-world data sets.
Hard-Clustering with Gaussian Mixture Models
Mar 21, 2016Training the parameters of statistical models to describe a given data set is a central task in the field of data mining and machine learning. A very popular and powerful way of parameter estimation is the method of maximum likelihood estimation (MLE). Among the most widely used families of statistical models are mixture models, especially, mixtures of Gaussian distributions. A popular hard-clustering variant of the MLE problem is the so-called complete-data maximum likelihood estimation (CMLE) method. The standard approach to solve the CMLE problem is the Classification-Expectation-Maximization (CEM) algorithm. Unfortunately, it is only guaranteed that the algorithm converges to some (possibly arbitrarily poor) stationary point of the objective function. In this paper, we present two algorithms for a restricted version of the CMLE problem. That is, our algorithms approximate reasonable solutions to the CMLE problem which satisfy certain natural properties. Moreover, they compute solutions whose cost (i.e. complete-data log-likelihood values) are at most a factor $(1+\epsilon)$ worse than the cost of the solutions that we search for. Note the CMLE problem in its most general, i.e. unrestricted, form is not well defined and allows for trivial optimal solutions that can be thought of as degenerated solutions.
Complexity and Approximation of the Fuzzy K-Means Problem
Dec 18, 2015
The fuzzy $K$-means problem is a generalization of the classical $K$-means problem to soft clusterings, i.e. clusterings where each points belongs to each cluster to some degree. Although popular in practice, prior to this work the fuzzy $K$-means problem has not been studied from a complexity theoretic or algorithmic perspective. We show that optimal solutions for fuzzy $K$-means cannot, in general, be expressed by radicals over the input points. Surprisingly, this already holds for very simple inputs in one-dimensional space. Hence, one cannot expect to compute optimal solutions exactly. We give the first $(1+\epsilon)$-approximation algorithms for the fuzzy $K$-means problem. First, we present a deterministic approximation algorithm whose runtime is polynomial in $N$ and linear in the dimension $D$ of the input set, given that $K$ is constant, i.e. a polynomial time approximation algorithm given a fixed $K$. We achieve this result by showing that for each soft clustering there exists a hard clustering with comparable properties. Second, by using techniques known from coreset constructions for the $K$-means problem, we develop a deterministic approximation algorithm that runs in time almost linear in $N$ but exponential in the dimension $D$. We complement these results with a randomized algorithm which imposes some natural restrictions on the input set and whose runtime is comparable to some of the most efficient approximation algorithms for $K$-means, i.e. linear in the number of points and the dimension, but exponential in the number of clusters.
A Theoretical and Experimental Comparison of the EM and SEM Algorithm
Jul 02, 2014

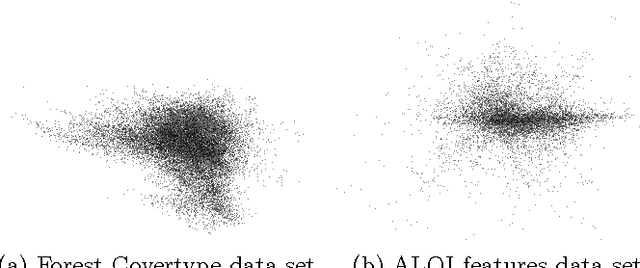
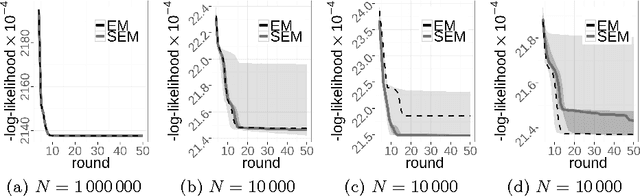
In this paper we provide a new analysis of the SEM algorithm. Unlike previous work, we focus on the analysis of a single run of the algorithm. First, we discuss the algorithm for general mixture distributions. Second, we consider Gaussian mixture models and show that with high probability the update equations of the EM algorithm and its stochastic variant are almost the same, given that the input set is sufficiently large. Our experiments confirm that this still holds for a large number of successive update steps. In particular, for Gaussian mixture models, we show that the stochastic variant runs nearly twice as fast.