 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Efficient Universal Classifiers with Natural Language Inference
Dec 29, 2023Generative Large Language Models (LLMs) have become the mainstream choice for fewshot and zeroshot learning thanks to the universality of text generation. Many users, however, do not need the broad capabilities of generative LLMs when they only want to automate a classification task. Smaller BERT-like models can also learn universal tasks, which allow them to do any text classification task without requiring fine-tuning (zeroshot classification) or to learn new tasks with only a few examples (fewshot), while being significantly more efficient than generative LLMs. This paper (1) explains how Natural Language Inference (NLI) can be used as a universal classification task that follows similar principles as instruction fine-tuning of generative LLMs, (2) provides a step-by-step guide with reusable Jupyter notebooks for building a universal classifier, and (3) shares the resulting universal classifier that is trained on 33 datasets with 389 diverse classes. Parts of the code we share has been used to train our older zeroshot classifiers that have been downloaded more than 55 million times via the Hugging Face Hub as of December 2023. Our new classifier improves zeroshot performance by 9.4%.
Beyond Discrete Genres: Mapping News Items onto a Multidimensional Framework of Genre Cues
Dec 08, 2022



In the contemporary media landscape, with the vast and diverse supply of news, it is increasingly challenging to study such an enormous amount of items without a standardized framework. Although attempts have been made to organize and compare news items on the basis of news values, news genres receive little attention, especially the genres in a news consumer's perception. Yet, perceived news genres serve as an essential component in exploring how news has developed, as well as a precondition for understanding media effects. We approach this concept by conceptualizing and operationalizing a non-discrete framework for mapping news items in terms of genre cues. As a starting point, we propose a preliminary set of dimensions consisting of "factuality" and "formality". To automatically analyze a large amount of news items, we deliver two computational models for predicting news sentences in terms of the said two dimensions. Such predictions could then be used for locating news items within our framework. This proposed approach that positions news items upon a multidimensional grid helps in deepening our insight into the evolving nature of news genres.
The semantic mapping of words and co-words in contexts
Jan 29, 2011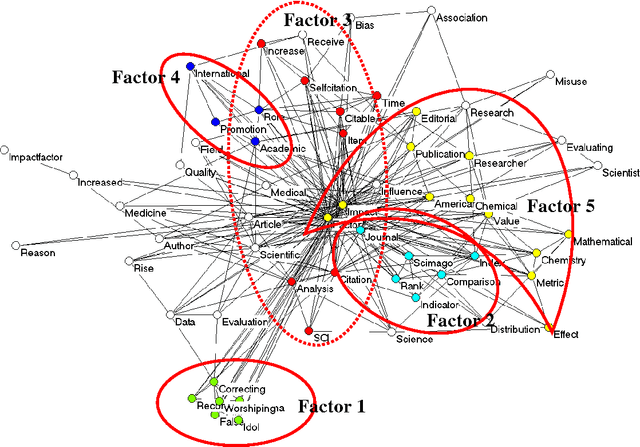
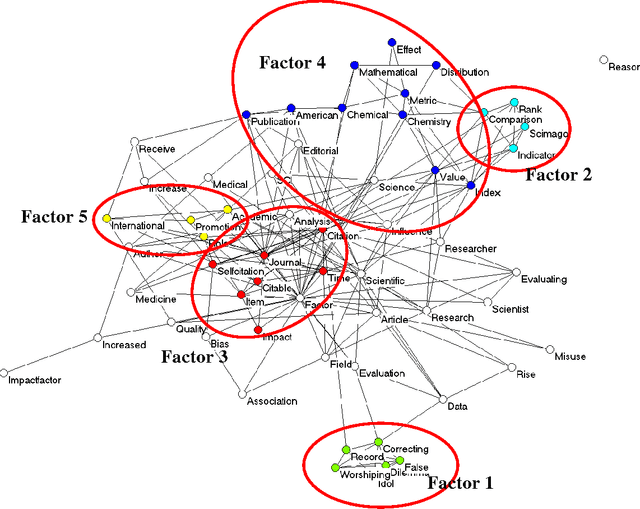
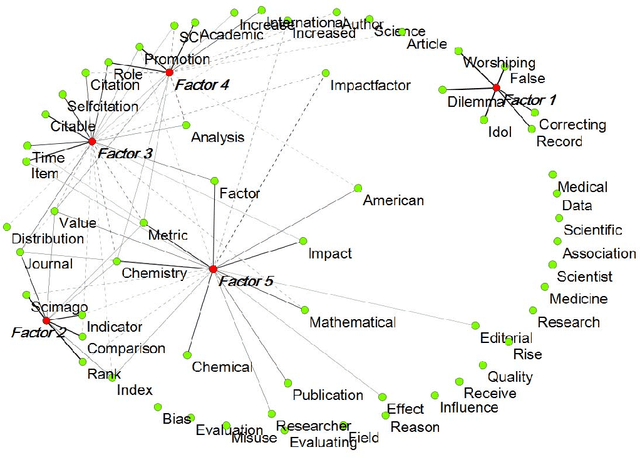
Meaning can be generated when information is related at a systemic level. Such a system can be an observer, but also a discourse, for example, operationalized as a set of documents. The measurement of semantics as similarity in patterns (correlations) and latent variables (factor analysis) has been enhanced by computer techniques and the use of statistics; for example, in "Latent Semantic Analysis". This communication provides an introduction, an example, pointers to relevant software, and summarizes the choices that can be made by the analyst. Visualization ("semantic mapping") is thus made more accessible.