 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Fast and Accurate Approach to Detection and Segmentation of Melanoma Skin Cancer using Fine-tuned Yolov3 and SegNet Based on Deep Transfer Learning
Oct 11, 2022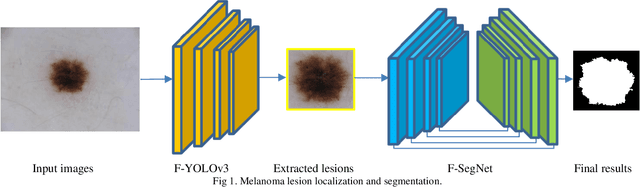


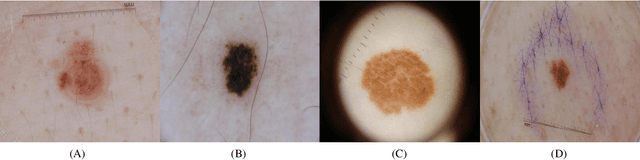
Melanoma is one of the most serious skin cancers that can occur in any part of the human skin. Early diagnosing melanoma lesions will significantly increase their chances of being cured. Improving melanoma segmentation will help doctors or surgical robots remove the lesion more accurately from body parts. Recently, the learning-based segmentation methods achieved desired results in image segmentation compared to traditional algorithms. This study proposes a new method to improve melanoma skin lesions detection and segmentation by defining a two-step pipeline based on deep learning models. Our methods were evaluated on ISIC 2018 (Skin Lesion Analysis Towards Melanoma Detection Challenge Dataset) well-known dataset. The proposed methods consist of two main parts for real-time detection of lesion location and segmentation. In the detection section, the location of the skin lesion is precisely detected by the fine-tuned You Only Look Once version 3 (F-YOLOv3) and then fed into the fine-tuned Segmentation Network (F-SegNet). Skin lesion localization helps to reduce the unnecessary calculation of whole images for segmentation. The results show that our proposed F-YOLOv3 achieves better performance as 96% in mAP. Compared to state-of-the-art segmentation approaches, our F-SegNet achieves higher performance for accuracy, dice coefficient, and Jaccard index at 95.16%, 92.81%, and 86.2%, respectively.
Attention-Guided Version of 2D UNet for Automatic Brain Tumor Segmentation
Apr 04, 2020
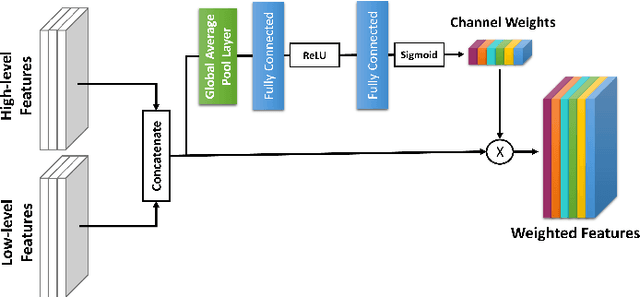
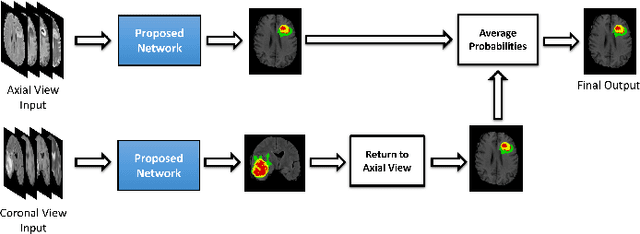
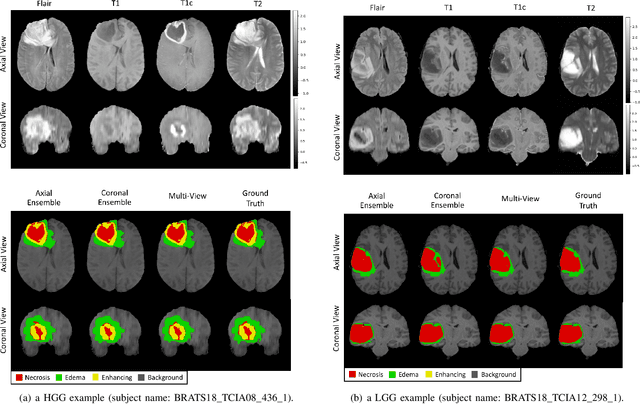
Gliomas are the most common and aggressive among brain tumors, which cause a short life expectancy in their highest grade. Therefore, treatment assessment is a key stage to enhance the quality of the patients' lives. Recently, deep convolutional neural networks (DCNNs) have achieved a remarkable performance in brain tumor segmentation, but this task is still difficult owing to high varying intensity and appearance of gliomas. Most of the existing methods, especially UNet-based networks, integrate low-level and high-level features in a naive way, which may result in confusion for the model. Moreover, most approaches employ 3D architectures to benefit from 3D contextual information of input images. These architectures contain more parameters and computational complexity than 2D architectures. On the other hand, using 2D models causes not to benefit from 3D contextual information of input images. In order to address the mentioned issues, we design a low-parameter network based on 2D UNet in which we employ two techniques. The first technique is an attention mechanism, which is adopted after concatenation of low-level and high-level features. This technique prevents confusion for the model by weighting each of the channels adaptively. The second technique is the Multi-View Fusion. By adopting this technique, we can benefit from 3D contextual information of input images despite using a 2D model. Experimental results demonstrate that our method performs favorably against 2017 and 2018 state-of-the-art methods.
* 7 pages, 5 figures, 4 tables, Accepted by ICCKE 2019