 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePDNet: Semantic Segmentation integrated with a Primal-Dual Network for Document binarization
May 17, 2018
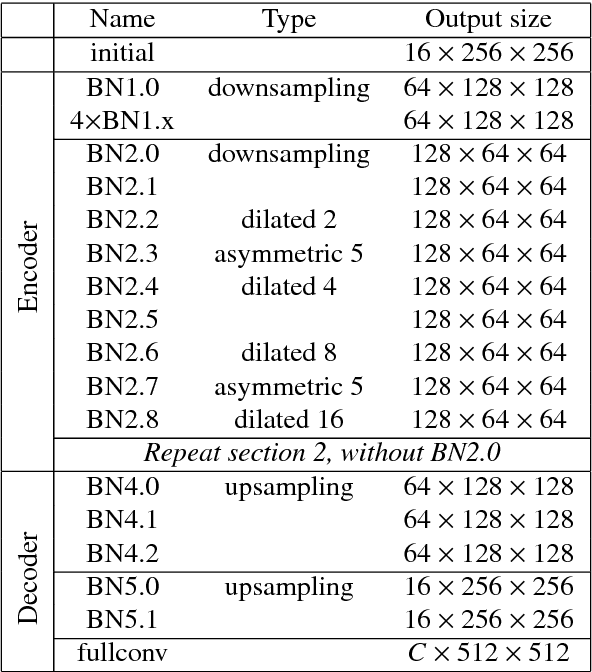


Binarization of digital documents is the task of classifying each pixel in an image of the document as belonging to the background (parchment/paper) or foreground (text/ink). Historical documents are often subjected to degradations, that make the task challenging. In the current work a deep neural network architecture is proposed that combines a fully convolutional network with an unrolled primal-dual network that can be trained end-to-end to achieve state of the art binarization on four out of seven datasets. Document binarization is formulated as an energy minimization problem. A fully convolutional neural network is trained for semantic segmentation of pixels that provides labeling cost associated with each pixel. This cost estimate is refined along the edges to compensate for any over or under estimation of the foreground class using a primal-dual approach. We provide necessary overview on proximal operator that facilitates theoretical underpinning required to train a primal-dual network using a gradient descent algorithm. Numerical instabilities encountered due to the recurrent nature of primal-dual approach are handled. We provide experimental results on document binarization competition dataset along with network changes and hyperparameter tuning required for stability and performance of the network. The network when pre-trained on synthetic dataset performs better as per the competition metrics.