 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Performance of Advanced NLP Models and LLMs in Multilingual Geo-Entity Detection
Dec 29, 2024The integration of advanced Natural Language Processing (NLP) methodologies and Large Language Models (LLMs) has significantly enhanced the extraction and analysis of geospatial data from multilingual texts, impacting sectors such as national and international security. This paper presents a comprehensive evaluation of leading NLP models -- SpaCy, XLM-RoBERTa, mLUKE, GeoLM -- and LLMs, specifically OpenAI's GPT 3.5 and GPT 4, within the context of multilingual geo-entity detection. Utilizing datasets from Telegram channels in English, Russian, and Arabic, we examine the performance of these models through metrics such as accuracy, precision, recall, and F1 scores, to assess their effectiveness in accurately identifying geospatial references. The analysis exposes each model's distinct advantages and challenges, underscoring the complexities involved in achieving precise geo-entity identification across varied linguistic landscapes. The conclusions drawn from this experiment aim to direct the enhancement and creation of more advanced and inclusive NLP tools, thus advancing the field of geospatial analysis and its application to global security.
A Multidisciplinary Approach to Telegram Data Analysis
Dec 29, 2024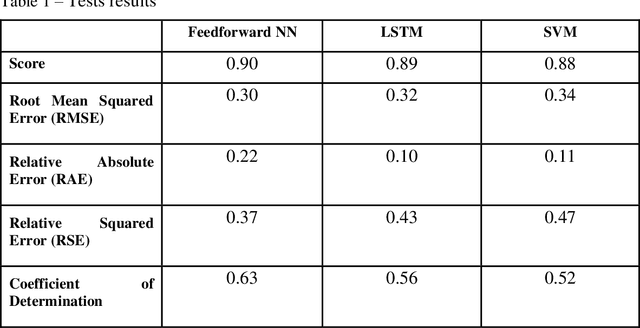

This paper presents a multidisciplinary approach to analyzing data from Telegram for early warning information regarding cyber threats. With the proliferation of hacktivist groups utilizing Telegram to disseminate information regarding future cyberattacks or to boast about successful ones, the need for effective data analysis methods is paramount. The primary challenge lies in the vast number of channels and the overwhelming volume of data, necessitating advanced techniques for discerning pertinent risks amidst the noise. To address this challenge, we employ a combination of neural network architectures and traditional machine learning algorithms. These methods are utilized to classify and identify potential cyber threats within the Telegram data. Additionally, sentiment analysis and entity recognition techniques are incorporated to provide deeper insights into the nature and context of the communicated information. The study evaluates the effectiveness of each method in detecting and categorizing cyber threats, comparing their performance and identifying areas for improvement. By leveraging these diverse analytical tools, we aim to enhance early warning systems for cyber threats, enabling more proactive responses to potential security breaches. This research contributes to the ongoing efforts to bolster cybersecurity measures in an increasingly interconnected digital landscape.