 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Polysemy Evolution Using Semantic Cells
Aug 06, 2024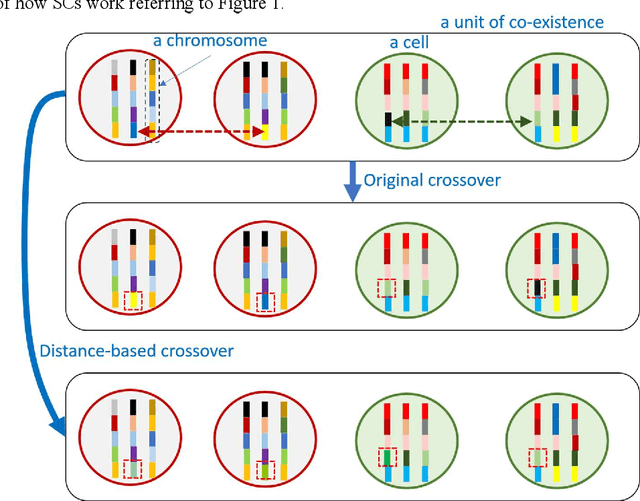
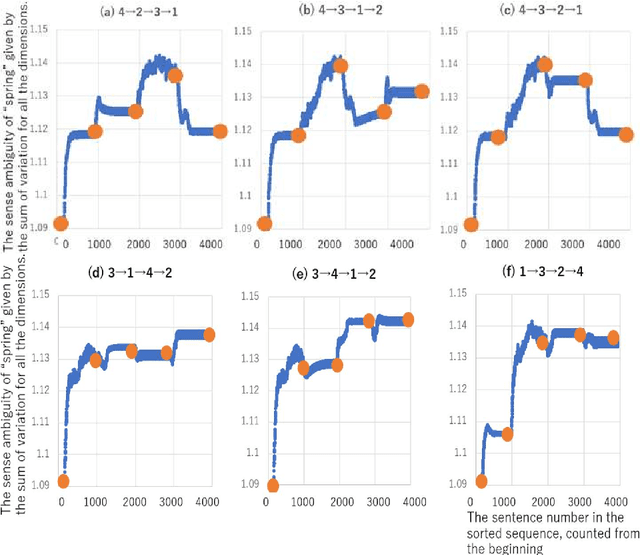
The senses of words evolve. The sense of the same word may change from today to tomorrow, and multiple senses of the same word may be the result of the evolution of each other, that is, they may be parents and children. If we view Juba as an evolving ecosystem, the paradigm of learning the correct answer, which does not move with the sense of a word, is no longer valid. This paper is a case study that shows that word polysemy is an evolutionary consequence of the modification of Semantic Cells, which has al-ready been presented by the author, by introducing a small amount of diversity in its initial state as an example of analyzing the current set of short sentences. In particular, the analysis of a sentence sequence of 1000 sentences in some order for each of the four senses of the word Spring, collected using Chat GPT, shows that the word acquires the most polysemy monotonically in the analysis when the senses are arranged in the order in which they have evolved. In other words, we present a method for analyzing the dynamism of a word's acquiring polysemy with evolution and, at the same time, a methodology for viewing polysemy from an evolutionary framework rather than a learning-based one.
Analyzing the Polysemy Evolution using Semantic Cells
Jul 23, 2024The senses of words evolve. The sense of the same word may change from today to tomorrow, and multiple senses of the same word may be the result of the evolution of each other, that is, they may be parents and children. If we view Juba as an evolving ecosystem, the paradigm of learning the correct answer, which does not move with the sense of a word, is no longer valid. This paper is a case study that shows that word polysemy is an evolutionary consequence of the modification of Semantic Cells, which has al-ready been presented by the author, by introducing a small amount of diversity in its initial state as an example of analyzing the current set of short sentences. In particular, the analysis of a sentence sequence of 1000 sentences in some order for each of the four senses of the word Spring, collected using Chat GPT, shows that the word acquires the most polysemy monotonically in the analysis when the senses are arranged in the order in which they have evolved. In other words, we present a method for analyzing the dynamism of a word's acquiring polysemy with evolution and, at the same time, a methodology for viewing polysemy from an evolutionary framework rather than a learning-based one.
Semantic Cells: Evolutional Process to Acquire Sense Diversity of Items
Apr 26, 2024Previous models for learning the semantic vectors of items and their groups, such as words, sentences, nodes, and graphs, using distributed representation have been based on the assumption that the basic sense of an item corresponds to one vector composed of dimensions corresponding to hidden contexts in the target real world, from which multiple senses of the item are obtained by conforming to lexical databases or adapting to the context. However, there may be multiple senses of an item, which are hardly assimilated and change or evolve dynamically following the contextual shift even within a document or a restricted period. This is a process similar to the evolution or adaptation of a living entity with/to environmental shifts. Setting the scope of disambiguation of items for sensemaking, the author presents a method in which a word or item in the data embraces multiple semantic vectors that evolve via interaction with others, similar to a cell embracing chromosomes crossing over with each other. We obtained two preliminary results: (1) the role of a word that evolves to acquire the largest or lower-middle variance of semantic vectors tends to be explainable by the author of the text; (2) the epicenters of earthquakes that acquire larger variance via crossover, corresponding to the interaction with diverse areas of land crust, are likely to correspond to the epicenters of forthcoming large earthquakes.
Collect and Connect Data Leaves to Feature Concepts: Interactive Graph Generation Toward Well-being
Dec 16, 2023Feature concepts and data leaves have been invented using datasets to foster creative thoughts for creating well-being in daily life. The idea, simply put, is to attach selected and collected data leaves that are summaries of event flows to be discovered from corresponding datasets, on the target feature concept representing the well-being aimed. A graph of existing or expected datasets to be attached to a feature concept is generated semi-automatically. Rather than sheer automated generative AI, our work addresses the process of generative artificial and natural intelligence to create the basis for data use and reuse.
Data Leaves: Scenario-oriented Metadata for Data Federative Innovation
Aug 07, 2022A method for representing the digest information of each dataset is proposed, oriented to the aid of innovative thoughts and the communication of data users who attempt to create valuable products, services, and business models using or combining datasets. Compared with methods for connecting datasets via shared attributes (i.e., variables), this method connects datasets via events, situations, or actions in a scenario that is supposed to be active in the real world. This method reflects the consideration of the fitness of each metadata to the feature concept, which is an abstract of the information or knowledge expected to be acquired from data; thus, the users of the data acquire practical knowledge that fits the requirements of real businesses and real life, as well as grounds for realistic application of AI technologies to data.