Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaVAC: Fine-tuning LLaVA as a Multimodal Sentiment Classifier
Feb 05, 2025
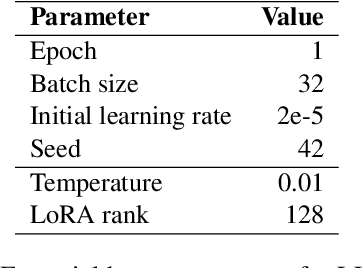

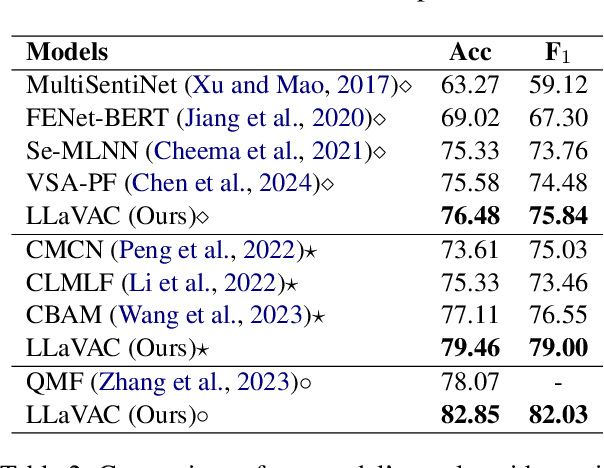
We present LLaVAC, a method for constructing a classifier for multimodal sentiment analysis. This method leverages fine-tuning of the Large Language and Vision Assistant (LLaVA) to predict sentiment labels across both image and text modalities. Our approach involves designing a structured prompt that incorporates both unimodal and multimodal labels to fine-tune LLaVA, enabling it to perform sentiment classification effectively. Experiments on the MVSA-Single dataset demonstrate that LLaVAC outperforms existing methods in multimodal sentiment analysis across three data processing procedures. The implementation of LLaVAC is publicly available at https://github.com/tchayintr/llavac.
Via