 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDestruction of Image Steganography using Generative Adversarial Networks
Dec 20, 2019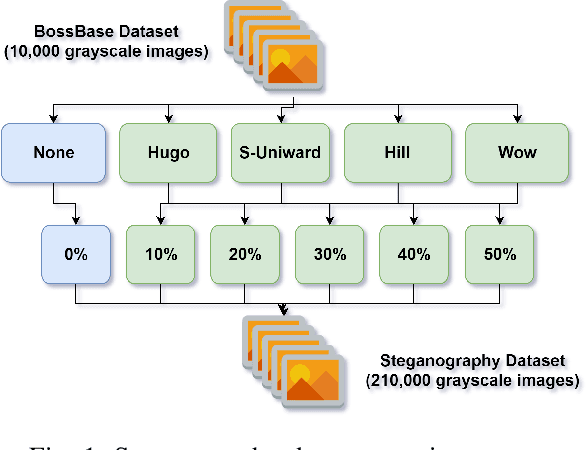


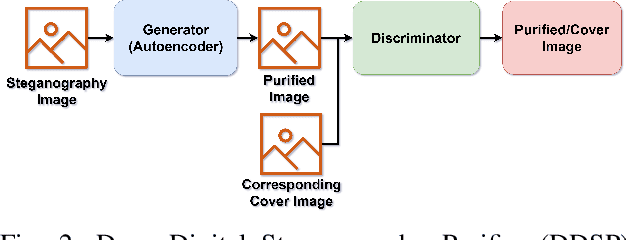
Digital image steganalysis, or the detection of image steganography, has been studied in depth for years and is driven by Advanced Persistent Threat (APT) groups', such as APT37 Reaper, utilization of steganographic techniques to transmit additional malware to perform further post-exploitation activity on a compromised host. However, many steganalysis algorithms are constrained to work with only a subset of all possible images in the wild or are known to produce a high false positive rate. This results in blocking any suspected image being an unreasonable policy. A more feasible policy is to filter suspicious images prior to reception by the host machine. However, how does one optimally filter specifically to obfuscate or remove image steganography while avoiding degradation of visual image quality in the case that detection of the image was a false positive? We propose the Deep Digital Steganography Purifier (DDSP), a Generative Adversarial Network (GAN) which is optimized to destroy steganographic content without compromising the perceptual quality of the original image. As verified by experimental results, our model is capable of providing a high rate of destruction of steganographic image content while maintaining a high visual quality in comparison to other state-of-the-art filtering methods. Additionally, we test the transfer learning capability of generalizing to to obfuscate real malware payloads embedded into different image file formats and types using an unseen steganographic algorithm and prove that our model can in fact be deployed to provide adequate results.
DomainGAN: Generating Adversarial Examples to Attack Domain Generation Algorithm Classifiers
Nov 18, 2019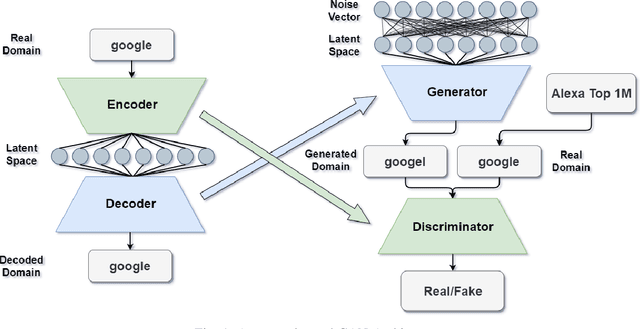
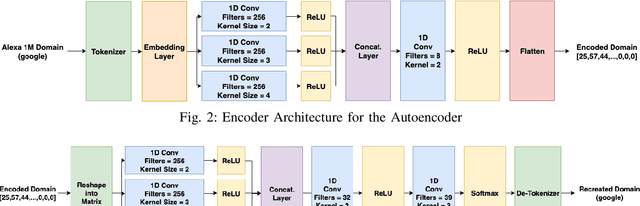
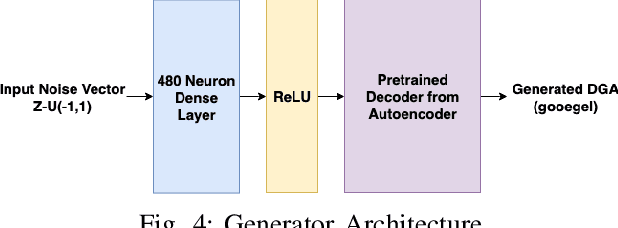
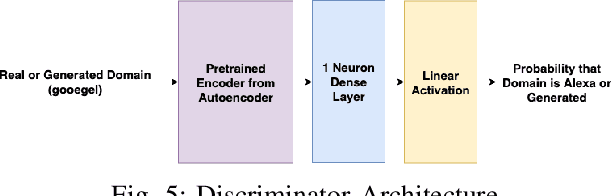
Domain Generation Algorithms (DGAs) are frequently used to generate numerous domains for use by botnets. These domains are often utilized as rendezvous points for servers that malware has command and control over. There are many algorithms that are used to generate domains, however many of these algorithms are simplistic and easily detected by traditional machine learning techniques. In this paper, three variants of Generative Adversarial Networks (GANs) are optimized to generate domains which have similar characteristics of benign domains, resulting in domains which greatly evade several state-of-the-art deep learning based DGA classifiers. We additionally provide a detailed analysis into offensive usability for each variant with respect to repeated and existing domain collisions. Finally, we fine-tune the state-of-the-art DGA classifiers by adding GAN generated samples to their original training datasets and analyze the changes in performance. Our results conclude that GAN based DGAs are superior in evading DGA classifiers in comparison to traditional DGAs, and of the variants, the Wasserstein GAN with Gradient Penalty (WGANGP) is the highest performing DGA for uses both offensively and defensively.