 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Domain Pretraining Interferes with Instruction Alignment: An Empirical Study of Adapter Merging in Medical LLMs
Jan 26, 2026Large language models (LLMs) show strong general capability but often struggle with medical terminology precision and safety-critical instruction following. We present a case study for adapter interference in safety-critical domains using a 14B-parameter base model through a two-stage LoRA pipeline: (1) domain-adaptive pre-training (PT) to inject broad medical knowledge via continued pre-training (DAPT), and (2) supervised fine-tuning (SFT) to align the model with medical question-answering behaviors through instruction-style data. To balance instruction-following ability and domain knowledge retention, we propose Weighted Adapter Merging, linearly combining SFT and PT adapters before exporting a merged base-model checkpoint. On a held-out medical validation set (F5/F6), the merged model achieves BLEU-4 = 16.38, ROUGE-1 = 20.42, ROUGE-2 = 4.60, and ROUGE-L = 11.54 under a practical decoding configuration. We further analyze decoding sensitivity and training stability with loss curves and controlled decoding comparisons.
Credit Card Fraud Detection Using Autoencoder Neural Network
Aug 30, 2019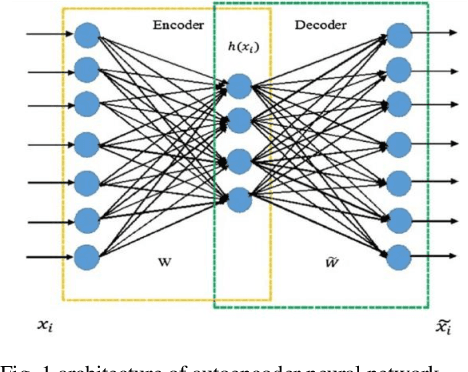

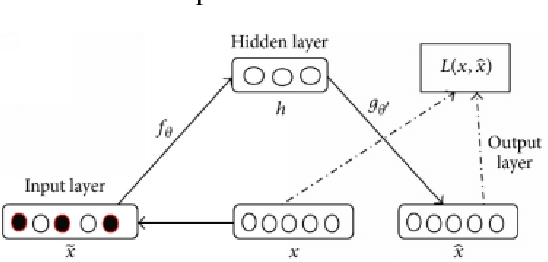

Imbalanced data classification problem has always been a popular topic in the field of machine learning research. In order to balance the samples between majority and minority class. Oversampling algorithm is used to synthesize new minority class samples, but it could bring in noise. Pointing to the noise problems, this paper proposed a denoising autoencoder neural network (DAE) algorithm which can not only oversample minority class sample through misclassification cost, but it can denoise and classify the sampled dataset. Through experiments, compared with the denoising autoencoder neural network (DAE) with oversampling process and traditional fully connected neural networks, the results showed the proposed algorithm improves the classification accuracy of minority class of imbalanced datasets.
Handwritten Chinese Character Recognition by Convolutional Neural Network and Similarity Ranking
Aug 30, 2019


Convolution Neural Networks (CNN) have recently achieved state-of-the art performance on handwritten Chinese character recognition (HCCR). However, most of CNN models employ the SoftMax activation function and minimize cross entropy loss, which may cause loss of inter-class information. To cope with this problem, we propose to combine cross entropy with similarity ranking function and use it as loss function. The experiments results show that the combination loss functions produce higher accuracy in HCCR. This report briefly reviews cross entropy loss function, a typical similarity ranking function: Euclidean distance, and also propose a new similarity ranking function: Average variance similarity. Experiments are done to compare the performances of a CNN model with three different loss functions. In the end, SoftMax cross entropy with Average variance similarity produce the highest accuracy on handwritten Chinese characters recognition.