 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAST: Mask-Guided Attention Mass Allocation for Training-Free Multi-Style Transfer
Apr 14, 2026Style transfer aims to render a content image with the visual characteristics of a reference style while preserving its underlying semantic layout and structural geometry. While recent diffusion-based models demonstrate strong stylization capabilities by leveraging powerful generative priors and controllable internal representations, they typically assume a single global style. Extending them to multi-style scenarios often leads to boundary artifacts, unstable stylization, and structural inconsistency due to interference between multiple style representations. To overcome these limitations, we propose MAST (Mask-Guided Attention Mass Allocation for Training-Free Multi-Style Transfer), a novel training-free framework that explicitly controls content-style interactions within the diffusion attention mechanism. To achieve artifact-free and structure-preserving stylization, MAST integrates four connected modules. First, Layout-preserving Query Anchoring prevents global layout collapse by firmly anchoring the semantic structure using content queries. Second, Logit-level Attention Mass Allocation deterministically distributes attention probability mass across spatial regions, seamlessly fusing multiple styles without boundary artifacts. Third, Sharpness-aware Temperature Scaling restores the attention sharpness degraded by multi-style expansion. Finally, Discrepancy-aware Detail Injection adaptively compensates for localized high-frequency detail losses by measuring structural discrepancies. Extensive experiments demonstrate that MAST effectively mitigates boundary artifacts and maintains structural consistency, preserving texture fidelity and spatial coherence even as the number of applied styles increases.
STONE Dataset: A Scalable Multi-Modal Surround-View 3D Traversability Dataset for Off-Road Robot Navigation
Mar 12, 2026Reliable off-road navigation requires accurate estimation of traversable regions and robust perception under diverse terrain and sensing conditions. However, existing datasets lack both scalability and multi-modality, which limits progress in 3D traversability prediction. In this work, we introduce STONE, a large-scale multi-modal dataset for off-road navigation. STONE provides (1) trajectory-guided 3D traversability maps generated by a fully automated, annotation-free pipeline, and (2) comprehensive surround-view sensing with synchronized 128-channel LiDAR, six RGB cameras, and three 4D imaging radars. The dataset covers a wide range of environments and conditions, including day and night, grasslands, farmlands, construction sites, and lakes. Our auto-labeling pipeline reconstructs dense terrain surfaces from LiDAR scans, extracts geometric attributes such as slope, elevation, and roughness, and assigns traversability labels beyond the robot's trajectory using a Mahalanobis-distance-based criterion. This design enables scalable, geometry-aware ground-truth construction without manual annotation. Finally, we establish a benchmark for voxel-level 3D traversability prediction and provide strong baselines under both single-modal and multi-modal settings. STONE is available at: https://konyul.github.io/STONE-dataset/
I2AM: Interpreting Image-to-Image Latent Diffusion Models via Attribution Maps
Jul 17, 2024



Large-scale diffusion models have made significant advancements in the field of image generation, especially through the use of cross-attention mechanisms that guide image formation based on textual descriptions. While the analysis of text-guided cross-attention in diffusion models has been extensively studied in recent years, its application in image-to-image diffusion models remains underexplored. This paper introduces the Image-to-Image Attribution Maps I2AM method, which aggregates patch-level cross-attention scores to enhance the interpretability of latent diffusion models across time steps, heads, and attention layers. I2AM facilitates detailed image-to-image attribution analysis, enabling observation of how diffusion models prioritize key features over time and head during the image generation process from reference images. Through extensive experiments, we first visualize the attribution maps of both generated and reference images, verifying that critical information from the reference image is effectively incorporated into the generated image, and vice versa. To further assess our understanding, we introduce a new evaluation metric tailored for reference-based image inpainting tasks. This metric, measuring the consistency between the attribution maps of generated and reference images, shows a strong correlation with established performance metrics for inpainting tasks, validating the potential use of I2AM in future research endeavors.
Text-to-Image Synthesis for Any Artistic Styles: Advancements in Personalized Artistic Image Generation via Subdivision and Dual Binding
Apr 08, 2024

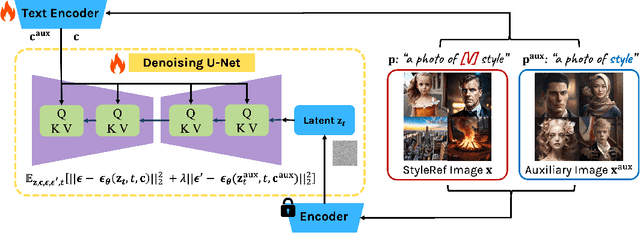

Recent advancements in text-to-image models, such as Stable Diffusion, have demonstrated their ability to synthesize visual images through natural language prompts. One approach of personalizing text-to-image models, exemplified by DreamBooth, fine-tunes the pre-trained model by binding unique text identifiers with a few images of a specific subject. Although existing fine-tuning methods have demonstrated competence in rendering images according to the styles of famous painters, it is still challenging to learn to produce images encapsulating distinct art styles due to abstract and broad visual perceptions of stylistic attributes such as lines, shapes, textures, and colors. In this paper, we introduce a new method, Single-StyleForge, for personalization. It fine-tunes pre-trained text-to-image diffusion models to generate diverse images in specified styles from text prompts. By using around 15-20 images of the target style, the approach establishes a foundational binding of a unique token identifier with a broad range of the target style. It also utilizes auxiliary images to strengthen this binding, resulting in offering specific guidance on representing elements such as persons in a target style-consistent manner. In addition, we present ways to improve the quality of style and text-image alignment through a method called Multi-StyleForge, which inherits the strategy used in StyleForge and learns tokens in multiple. Experimental evaluation conducted on six distinct artistic styles demonstrates substantial improvements in both the quality of generated images and the perceptual fidelity metrics, such as FID, KID, and CLIP scores.