 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken Communication-Driven Multimodal Large Models in Resource-Constrained Multiuser Networks
May 06, 2025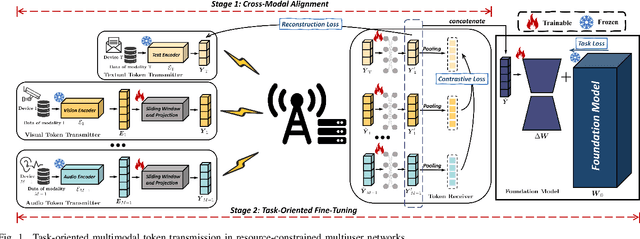
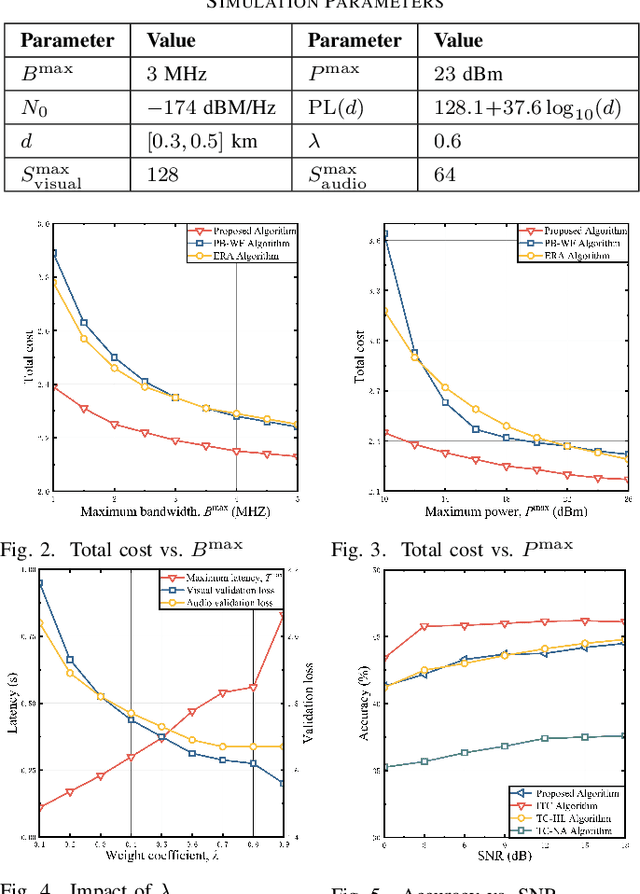
The proliferation of intelligent applications at the wireless edge, alongside the exponential growth of multimodal data, poses challenges for deploying multimodal large models (MLMs) in resource-constrained networks. These constraints manifest as limited bandwidth, computational capacity, and stringent latency requirements, particularly under low signal-to-noise ratio (SNR) conditions. To overcome these limitations, we propose a token communication paradigm that facilitates the decentralized deployment of MLMs across user devices and edge infrastructure (e.g., base stations). In this paradigm, task-relevant tokens are extracted from multimodal inputs and serve as the primary medium for communication between distributed model components. To align semantics and optimize transmission efficiency, we propose a dual-pronged approach: 1) We design a contrastive split fine-tuning method to project heterogeneous modalities into a shared feature space, enabling seamless interaction between model components while preserving modal-specific semantics. 2) We employ a lightweight compression technique to reduce the size of transmitted tokens, minimizing bandwidth consumption without sacrificing task-critical information. The proposed framework integrates collaborative fine-tuning of both the foundation model and multimodal transceivers, ensuring that token generation and utilization are tailored to specific downstream tasks. Simulation experiments conducted under different SNR conditions demonstrate that our method results in a $13.7\%$ improvement in test accuracy. Furthermore, our approach exhibits quicker convergence rates, even with reduced token lengths, highlighting the promise of token communication for facilitating more scalable and resilient MLM implementations in practical multiuser networks.
Federated Split Learning with Model Pruning and Gradient Quantization in Wireless Networks
Dec 10, 2024As a paradigm of distributed machine learning, federated learning typically requires all edge devices to train a complete model locally. However, with the increasing scale of artificial intelligence models, the limited resources on edge devices often become a bottleneck for efficient fine-tuning. To address this challenge, federated split learning (FedSL) implements collaborative training across the edge devices and the server through model splitting. In this paper, we propose a lightweight FedSL scheme, that further alleviates the training burden on resource-constrained edge devices by pruning the client-side model dynamicly and using quantized gradient updates to reduce computation overhead. Additionally, we apply random dropout to the activation values at the split layer to reduce communication overhead. We conduct theoretical analysis to quantify the convergence performance of the proposed scheme. Finally, simulation results verify the effectiveness and advantages of the proposed lightweight FedSL in wireless network environments.