 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Memorization in Sample Selection for Learning with Noisy Labels
Jul 08, 2021
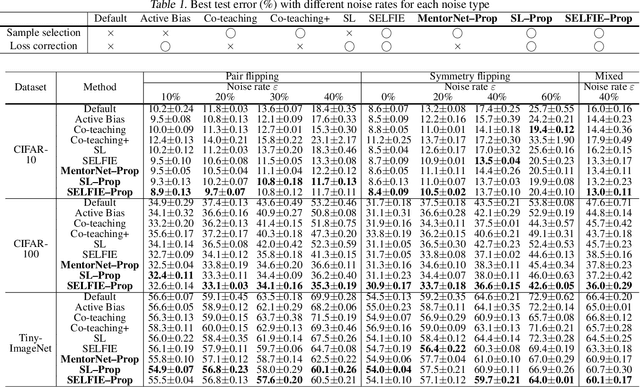
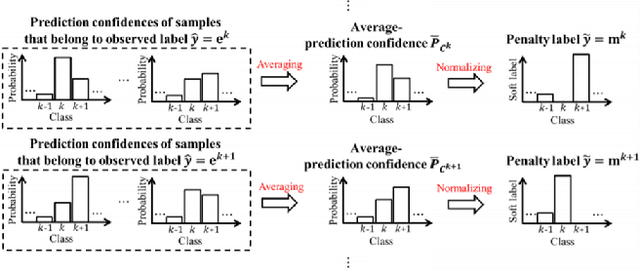
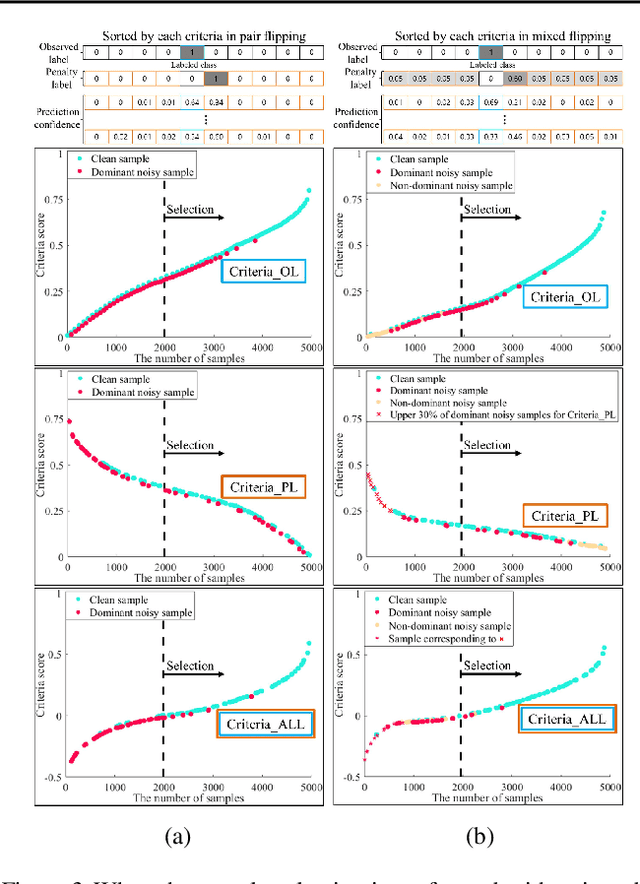
Because deep learning is vulnerable to noisy labels, sample selection techniques, which train networks with only clean labeled data, have attracted a great attention. However, if the labels are dominantly corrupted by few classes, these noisy samples are called dominant-noisy-labeled samples, the network also learns dominant-noisy-labeled samples rapidly via content-aware optimization. In this study, we propose a compelling criteria to penalize dominant-noisy-labeled samples intensively through class-wise penalty labels. By averaging prediction confidences for the each observed label, we obtain suitable penalty labels that have high values if the labels are largely corrupted by some classes. Experiments were performed using benchmarks (CIFAR-10, CIFAR-100, Tiny-ImageNet) and real-world datasets (ANIMAL-10N, Clothing1M) to evaluate the proposed criteria in various scenarios with different noise rates. Using the proposed sample selection, the learning process of the network becomes significantly robust to noisy labels compared to existing methods in several noise types.