 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChinese Medical Question Answer Matching Based on Interactive Sentence Representation Learning
Nov 27, 2020

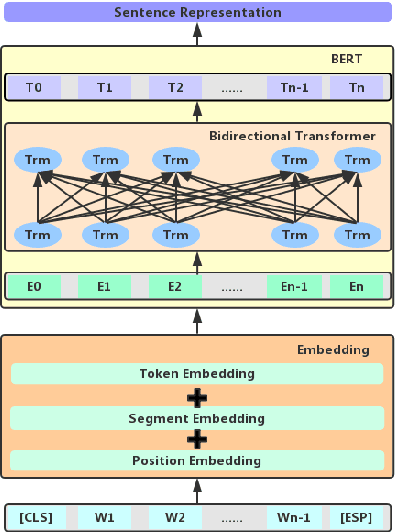

Chinese medical question-answer matching is more challenging than the open-domain question answer matching in English. Even though the deep learning method has performed well in improving the performance of question answer matching, these methods only focus on the semantic information inside sentences, while ignoring the semantic association between questions and answers, thus resulting in performance deficits. In this paper, we design a series of interactive sentence representation learning models to tackle this problem. To better adapt to Chinese medical question-answer matching and take the advantages of different neural network structures, we propose the Crossed BERT network to extract the deep semantic information inside the sentence and the semantic association between question and answer, and then combine with the multi-scale CNNs network or BiGRU network to take the advantage of different structure of neural networks to learn more semantic features into the sentence representation. The experiments on the cMedQA V2.0 and cMedQA V1.0 dataset show that our model significantly outperforms all the existing state-of-the-art models of Chinese medical question answer matching.
Joint Extraction of Entity and Relation with Information Redundancy Elimination
Nov 27, 2020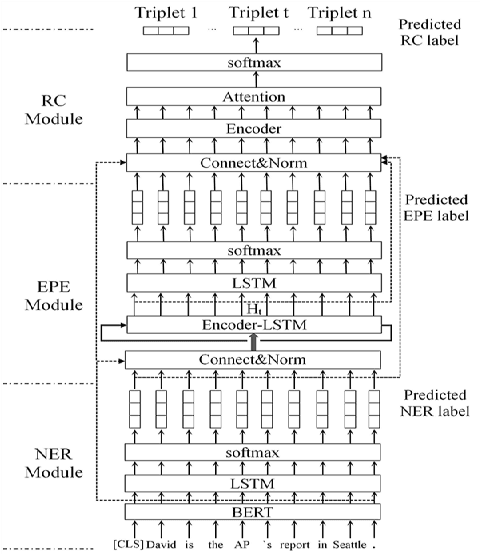
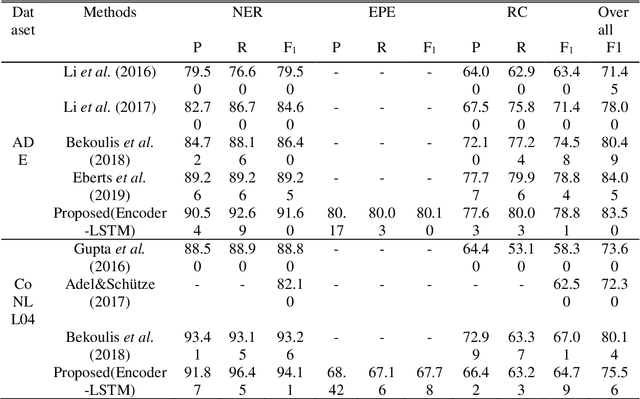
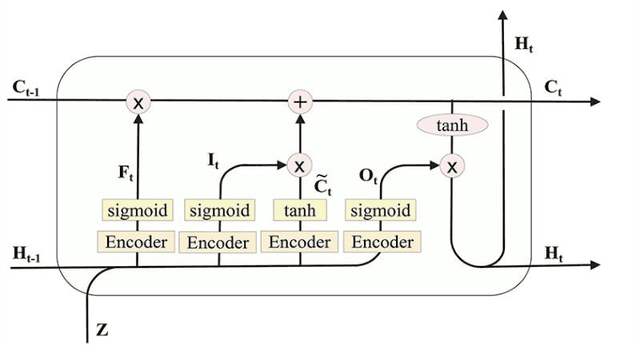
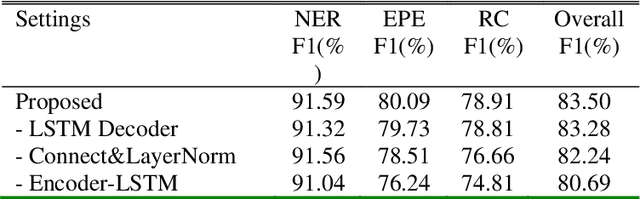
To solve the problem of redundant information and overlapping relations of the entity and relation extraction model, we propose a joint extraction model. This model can directly extract multiple pairs of related entities without generating unrelated redundant information. We also propose a recurrent neural network named Encoder-LSTM that enhances the ability of recurrent units to model sentences. Specifically, the joint model includes three sub-modules: the Named Entity Recognition sub-module consisted of a pre-trained language model and an LSTM decoder layer, the Entity Pair Extraction sub-module which uses Encoder-LSTM network to model the order relationship between related entity pairs, and the Relation Classification sub-module including Attention mechanism. We conducted experiments on the public datasets ADE and CoNLL04 to evaluate the effectiveness of our model. The results show that the proposed model achieves good performance in the task of entity and relation extraction and can greatly reduce the amount of redundant information.