 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHBIC: A Biclustering Algorithm for Heterogeneous Datasets
Aug 23, 2024Biclustering is an unsupervised machine-learning approach aiming to cluster rows and columns simultaneously in a data matrix. Several biclustering algorithms have been proposed for handling numeric datasets. However, real-world data mining problems often involve heterogeneous datasets with mixed attributes. To address this challenge, we introduce a biclustering approach called HBIC, capable of discovering meaningful biclusters in complex heterogeneous data, including numeric, binary, and categorical data. The approach comprises two stages: bicluster generation and bicluster model selection. In the initial stage, several candidate biclusters are generated iteratively by adding and removing rows and columns based on the frequency of values in the original matrix. In the second stage, we introduce two approaches for selecting the most suitable biclusters by considering their size and homogeneity. Through a series of experiments, we investigated the suitability of our approach on a synthetic benchmark and in a biomedical application involving clinical data of systemic sclerosis patients. The evaluation comparing our method to existing approaches demonstrates its ability to discover high-quality biclusters from heterogeneous data. Our biclustering approach is a starting point for heterogeneous bicluster discovery, leading to a better understanding of complex underlying data structures.
Biclustering Algorithms Based on Metaheuristics: A Review
Mar 30, 2022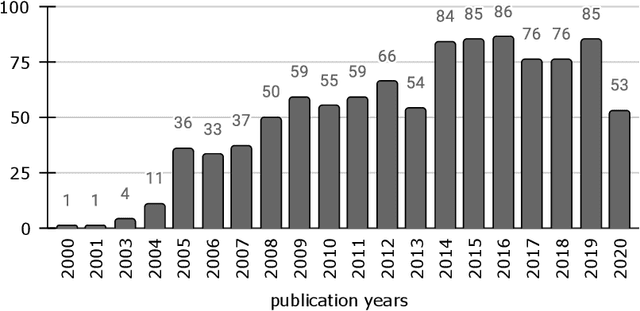
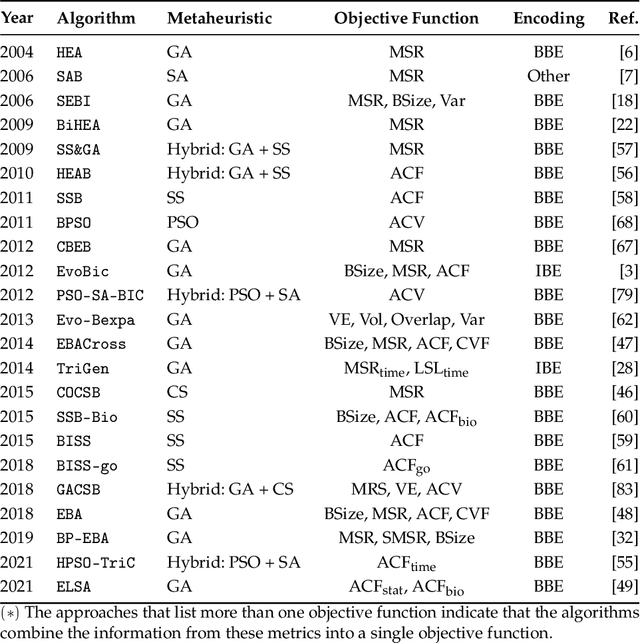
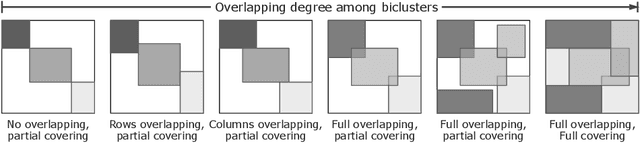
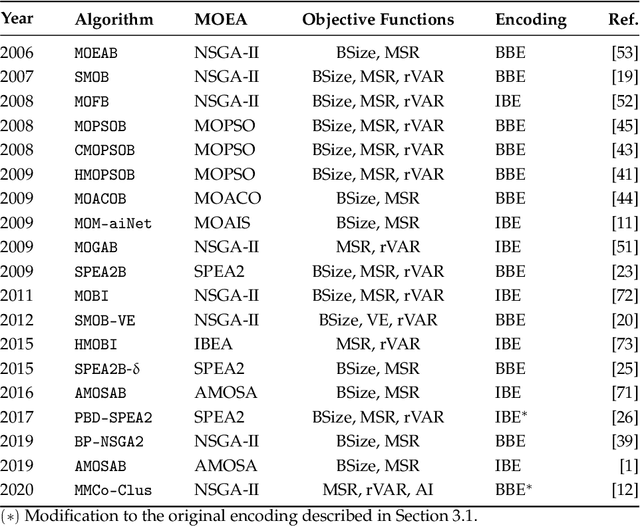
Biclustering is an unsupervised machine learning technique that simultaneously clusters rows and columns in a data matrix. Biclustering has emerged as an important approach and plays an essential role in various applications such as bioinformatics, text mining, and pattern recognition. However, finding significant biclusters is an NP-hard problem that can be formulated as an optimization problem. Therefore, different metaheuristics have been applied to biclustering problems because of their exploratory capability of solving complex optimization problems in reasonable computation time. Although various surveys on biclustering have been proposed, there is a lack of a comprehensive survey on the biclustering problem using metaheuristics. This chapter will present a survey of metaheuristics approaches to address the biclustering problem. The review focuses on the underlying optimization methods and their main search components: representation, objective function, and variation operators. A specific discussion on single versus multi-objective approaches is presented. Finally, some emerging research directions are presented.