 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelection as Power: Constrained Reinforcement for Bounded Decision Authority
Mar 02, 2026Selection as Power argued that upstream selection authority, rather than internal objective misalignment, constitutes a primary source of risk in high-stakes agentic systems. However, the original framework was static: governance constraints bounded selection power but did not adapt over time. In this work, we extend the framework to dynamic settings by introducing incentivized selection governance, where reinforcement updates are applied to scoring and reducer parameters under externally enforced sovereignty constraints. We formalize selection as a constrained reinforcement process in which parameter updates are projected onto governance-defined feasible sets, preventing concentration beyond prescribed bounds. Across multiple regulated financial scenarios, unconstrained reinforcement consistently collapses into deterministic dominance under repeated feedback, especially at higher learning rates. In contrast, incentivized governance enables adaptive improvement while maintaining bounded selection concentration. Projection-based constraints transform reinforcement from irreversible lock-in into controlled adaptation, with governance debt quantifying the tension between optimization pressure and authority bounds. These results demonstrate that learning dynamics can coexist with structural diversity when sovereignty constraints are enforced at every update step, offering a principled approach to integrating reinforcement into high-stakes agentic systems without surrendering bounded selection authority.
Towards Selection as Power: Bounding Decision Authority in Autonomous Agents
Feb 16, 2026Autonomous agentic systems are increasingly deployed in regulated, high-stakes domains where decisions may be irreversible and institutionally constrained. Existing safety approaches emphasize alignment, interpretability, or action-level filtering. We argue that these mechanisms are necessary but insufficient because they do not directly govern selection power: the authority to determine which options are generated, surfaced, and framed for decision. We propose a governance architecture that separates cognition, selection, and action into distinct domains and models autonomy as a vector of sovereignty. Cognitive autonomy remains unconstrained, while selection and action autonomy are bounded through mechanically enforced primitives operating outside the agent's optimization space. The architecture integrates external candidate generation (CEFL), a governed reducer, commit-reveal entropy isolation, rationale validation, and fail-loud circuit breakers. We evaluate the system across multiple regulated financial scenarios under adversarial stress targeting variance manipulation, threshold gaming, framing skew, ordering effects, and entropy probing. Metrics quantify selection concentration, narrative diversity, governance activation cost, and failure visibility. Results show that mechanical selection governance is implementable, auditable, and prevents deterministic outcome capture while preserving reasoning capacity. Although probabilistic concentration remains, the architecture measurably bounds selection authority relative to conventional scalar pipelines. This work reframes governance as bounded causal power rather than internal intent alignment, offering a foundation for deploying autonomous agents where silent failure is unacceptable.
Self-Evolving Coordination Protocol in Multi-Agent AI Systems: An Exploratory Systems Feasibility Study
Feb 02, 2026Contemporary multi-agent systems increasingly rely on internal coordination mechanisms to combine, arbitrate, or constrain the outputs of heterogeneous components. In safety-critical and regulated domains such as finance, these mechanisms must satisfy strict formal requirements, remain auditable, and operate within explicitly bounded limits. Coordination logic therefore functions as a governance layer rather than an optimization heuristic. This paper presents an exploratory systems feasibility study of Self-Evolving Coordination Protocols (SECP): coordination protocols that permit limited, externally validated self-modification while preserving fixed formal invariants. We study a controlled proof-of-concept setting in which six fixed Byzantine consensus protocol proposals are evaluated by six specialized decision modules. All coordination regimes operate under identical hard constraints, including Byzantine fault tolerance (f < n/3), O(n2) message complexity, complete non-statistical safety and liveness arguments, and bounded explainability. Four coordination regimes are compared in a single-shot design: unanimous hard veto, weighted scalar aggregation, SECP v1.0 (an agent-designed non-scalar protocol), and SECP v2.0 (the result of one governed modification). Outcomes are evaluated using a single metric, proposal coverage, defined as the number of proposals accepted. A single recursive modification increased coverage from two to three accepted proposals while preserving all declared invariants. The study makes no claims regarding statistical significance, optimality, convergence, or learning. Its contribution is architectural: it demonstrates that bounded self-modification of coordination protocols is technically implementable, auditable, and analyzable under explicit formal constraints, establishing a foundation for governed multi-agent systems.
Monetizing Currency Pair Sentiments through LLM Explainability
Jul 29, 2024


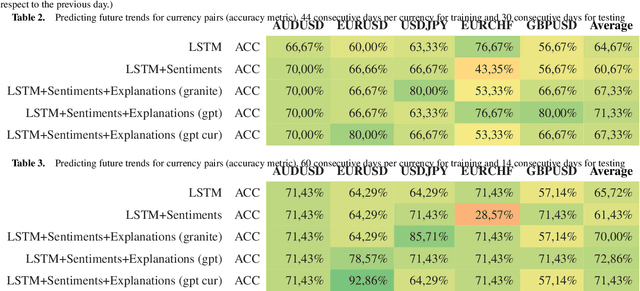
Large language models (LLMs) play a vital role in almost every domain in today's organizations. In the context of this work, we highlight the use of LLMs for sentiment analysis (SA) and explainability. Specifically, we contribute a novel technique to leverage LLMs as a post-hoc model-independent tool for the explainability of SA. We applied our technique in the financial domain for currency-pair price predictions using open news feed data merged with market prices. Our application shows that the developed technique is not only a viable alternative to using conventional eXplainable AI but can also be fed back to enrich the input to the machine learning (ML) model to better predict future currency-pair values. We envision our results could be generalized to employing explainability as a conventional enrichment for ML input for better ML predictions in general.