 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-training vision models for the classification of alerts from wide-field time-domain surveys
Dec 12, 2025Modern wide-field time-domain surveys facilitate the study of transient, variable and moving phenomena by conducting image differencing and relaying alerts to their communities. Machine learning tools have been used on data from these surveys and their precursors for more than a decade, and convolutional neural networks (CNNs), which make predictions directly from input images, saw particularly broad adoption through the 2010s. Since then, continually rapid advances in computer vision have transformed the standard practices around using such models. It is now commonplace to use standardized architectures pre-trained on large corpora of everyday images (e.g., ImageNet). In contrast, time-domain astronomy studies still typically design custom CNN architectures and train them from scratch. Here, we explore the affects of adopting various pre-training regimens and standardized model architectures on the performance of alert classification. We find that the resulting models match or outperform a custom, specialized CNN like what is typically used for filtering alerts. Moreover, our results show that pre-training on galaxy images from Galaxy Zoo tends to yield better performance than pre-training on ImageNet or training from scratch. We observe that the design of standardized architectures are much better optimized than the custom CNN baseline, requiring significantly less time and memory for inference despite having more trainable parameters. On the eve of the Legacy Survey of Space and Time and other image-differencing surveys, these findings advocate for a paradigm shift in the creation of vision models for alerts, demonstrating that greater performance and efficiency, in time and in data, can be achieved by adopting the latest practices from the computer vision field.
Decentralized Multi-Agent Reinforcement Learning with Global State Prediction
Jun 22, 2023
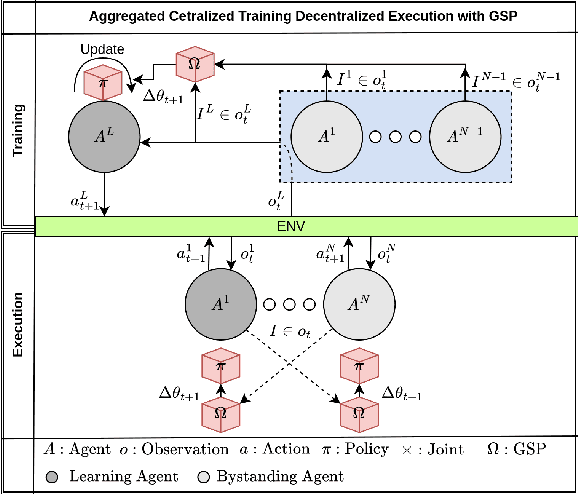


Deep reinforcement learning (DRL) has seen remarkable success in the control of single robots. However, applying DRL to robot swarms presents significant challenges. A critical challenge is non-stationarity, which occurs when two or more robots update individual or shared policies concurrently, thereby engaging in an interdependent training process with no guarantees of convergence. Circumventing non-stationarity typically involves training the robots with global information about other agents' states and/or actions. In contrast, in this paper we explore how to remove the need for global information. We pose our problem as a Partially Observable Markov Decision Process, due to the absence of global knowledge on other agents. Using collective transport as a testbed scenario, we study two approaches to multi-agent training. In the first, the robots exchange no messages, and are trained to rely on implicit communication through push-and-pull on the object to transport. In the second approach, we introduce Global State Prediction (GSP), a network trained to forma a belief over the swarm as a whole and predict its future states. We provide a comprehensive study over four well-known deep reinforcement learning algorithms in environments with obstacles, measuring performance as the successful transport of the object to the goal within a desired time-frame. Through an ablation study, we show that including GSP boosts performance and increases robustness when compared with methods that use global knowledge.
A Study of Reinforcement Learning Algorithms for Aggregates of Minimalistic Robots
Mar 28, 2022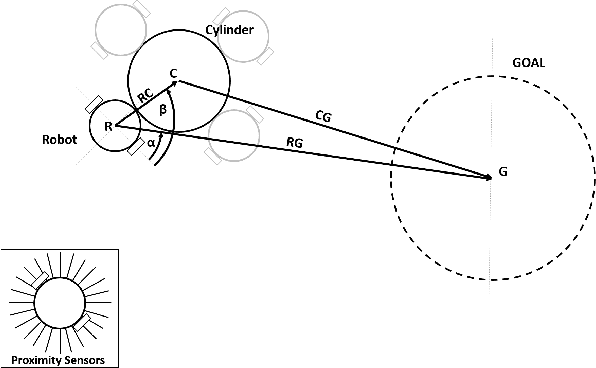
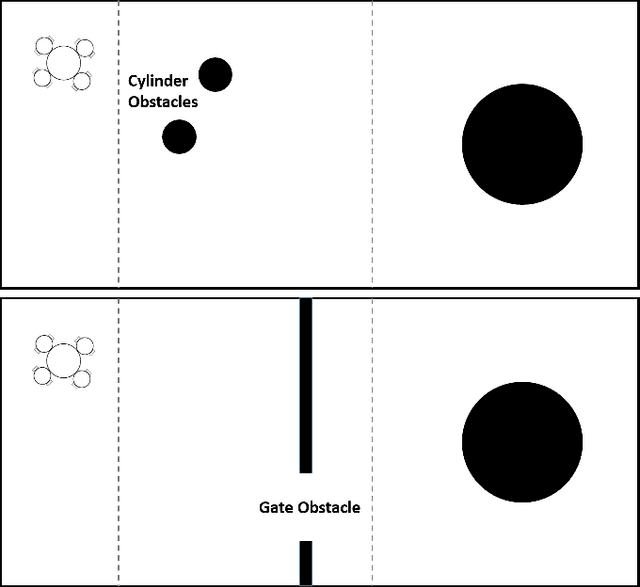
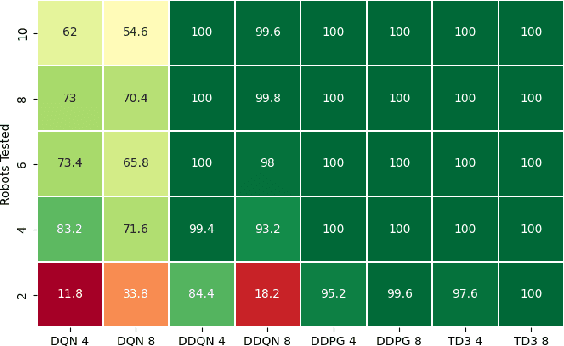

The aim of this paper is to study how to apply deep reinforcement learning for the control of aggregates of minimalistic robots. We define aggregates as groups of robots with a physical connection that compels them to form a specified shape. In our case, the robots are pre-attached to an object that must be collectively transported to a known location. Minimalism, in our setting, stems from the barebone capabilities we assume: The robots can sense the target location and the immediate obstacles, but lack the means to communicate explicitly through, e.g., message-passing. In our setting, communication is implicit, i.e., mediated by aggregated push-and-pull on the object exerted by each robot. We analyze the ability to reach coordinated behavior of four well-known algorithms for deep reinforcement learning (DQN, DDQN, DDPG, and TD3). Our experiments include robot failures and different types of environmental obstacles. We compare the performance of the best control strategies found, highlighting strengths and weaknesses of each of the considered training algorithms.