 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataflow Dialogue Generation
Aug 04, 2023



We demonstrate task-oriented dialogue generation within the dataflow dialogue paradigm. We show an example of agenda driven dialogue generation for the MultiWOZ domain, and an example of generation without an agenda for the SMCalFlow domain, where we show an improvement in the accuracy of the translation of user requests to dataflow expressions when the generated dialogues are used to augment the translation training dataset.
MultiWOZ-DF -- A Dataflow implementation of the MultiWOZ dataset
Nov 04, 2022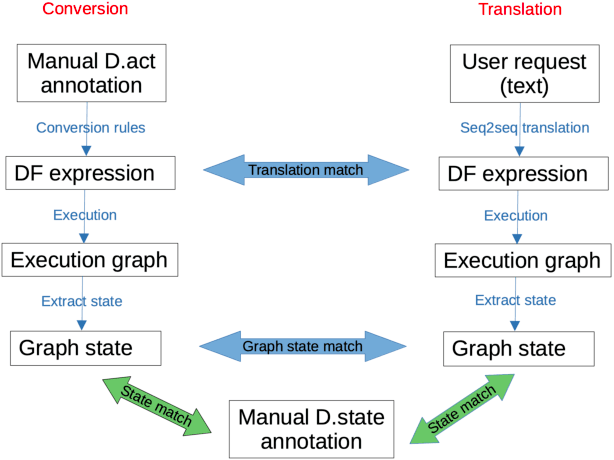



Semantic Machines (SM) have introduced the use of the dataflow (DF) paradigm to dialogue modelling, using computational graphs to hierarchically represent user requests, data, and the dialogue history [Semantic Machines et al. 2020]. Although the main focus of that paper was the SMCalFlow dataset (to date, the only dataset with "native" DF annotations), they also reported some results of an experiment using a transformed version of the commonly used MultiWOZ dataset [Budzianowski et al. 2018] into a DF format. In this paper, we expand the experiments using DF for the MultiWOZ dataset, exploring some additional experimental set-ups. The code and instructions to reproduce the experiments reported here have been released. The contributions of this paper are: 1.) A DF implementation capable of executing MultiWOZ dialogues; 2.) Several versions of conversion of MultiWOZ into a DF format are presented; 3.) Experimental results on state match and translation accuracy.
Simplifying Dataflow Dialogue Design
Jun 28, 2022



In \citep{andreas2020task-oriented}, a dataflow (DF) based dialogue system was introduced, showing clear advantages compared to many commonly used current systems. This was accompanied by the release of SMCalFlow, a practically relevant, manually annotated dataset, more detailed and much larger than any comparable dialogue dataset. Despite these remarkable contributions, the community has not shown further interest in this direction. What are the reasons for this lack of interest? And how can the community be encouraged to engage in research in this direction? One explanation may be the perception that this approach is too complex - both the the annotation and the system. This paper argues that this perception is wrong: 1) Suggestions for a simplified format for the annotation of the dataset are presented, 2) An implementation of the DF execution engine is released\footnote{https://github.com/telepathylabsai/OpenDF}, which can serve as a sandbox allowing researchers to easily implement, and experiment with, new DF dialogue designs. The hope is that these contributions will help engage more practitioners in exploring new ideas and designs for DF based dialogue systems.
Simplifying Semantic Annotations of SMCalFlow
Jun 27, 2022

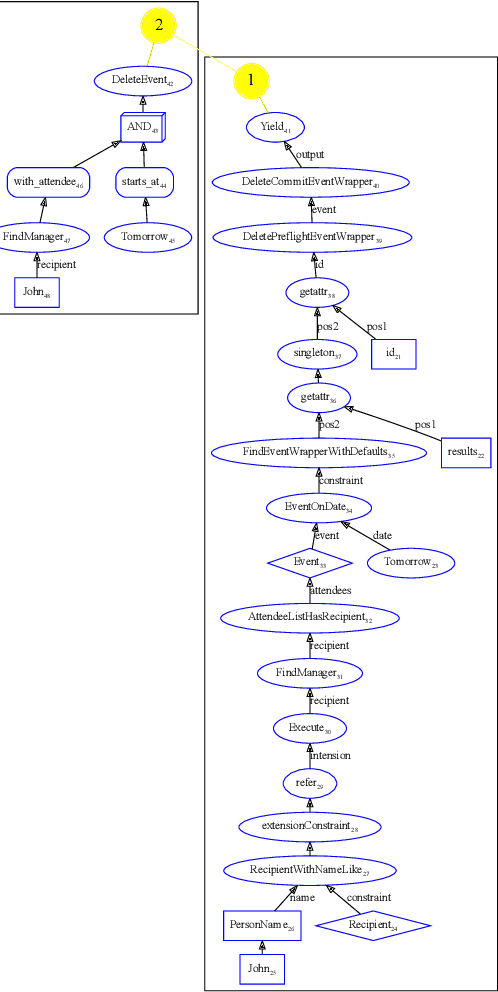
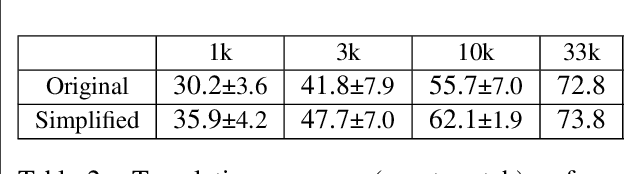
SMCalFlow is a large corpus of semantically detailed annotations of task-oriented natural dialogues. The annotations use a dataflow approach, in which the annotations are programs which represent user requests. Despite the availability, size and richness of this annotated corpus, it has seen only very limited use in dialogue systems research work, at least in part due to the difficulty in understanding and using the annotations. To address these difficulties, this paper suggests a simplification of the SMCalFlow annotations, as well as releases code needed to inspect the execution of the annotated dataflow programs, which should allow researchers of dialogue systems an easy entry point to experiment with various dataflow based implementations and annotations.
* Published in the Proceedings of the 18th Joint ACL - ISO Workshop on Interoperable Semantic Annotation within LREC2022