 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust online active learning
Feb 01, 2023In many industrial applications, obtaining labeled observations is not straightforward as it often requires the intervention of human experts or the use of expensive testing equipment. In these circumstances, active learning can be highly beneficial in suggesting the most informative data points to be used when fitting a model. Reducing the number of observations needed for model development alleviates both the computational burden required for training and the operational expenses related to labeling. Online active learning, in particular, is useful in high-volume production processes where the decision about the acquisition of the label for a data point needs to be taken within an extremely short time frame. However, despite the recent efforts to develop online active learning strategies, the behavior of these methods in the presence of outliers has not been thoroughly examined. In this work, we investigate the performance of online active linear regression in contaminated data streams. Our study shows that the currently available query strategies are prone to sample outliers, whose inclusion in the training set eventually degrades the predictive performance of the models. To address this issue, we propose a solution that bounds the search area of a conditional D-optimal algorithm and uses a robust estimator. Our approach strikes a balance between exploring unseen regions of the input space and protecting against outliers. Through numerical simulations, we show that the proposed method is effective in improving the performance of online active learning in the presence of outliers, thus expanding the potential applications of this powerful tool.
Stream-based active learning with linear models
Jul 20, 2022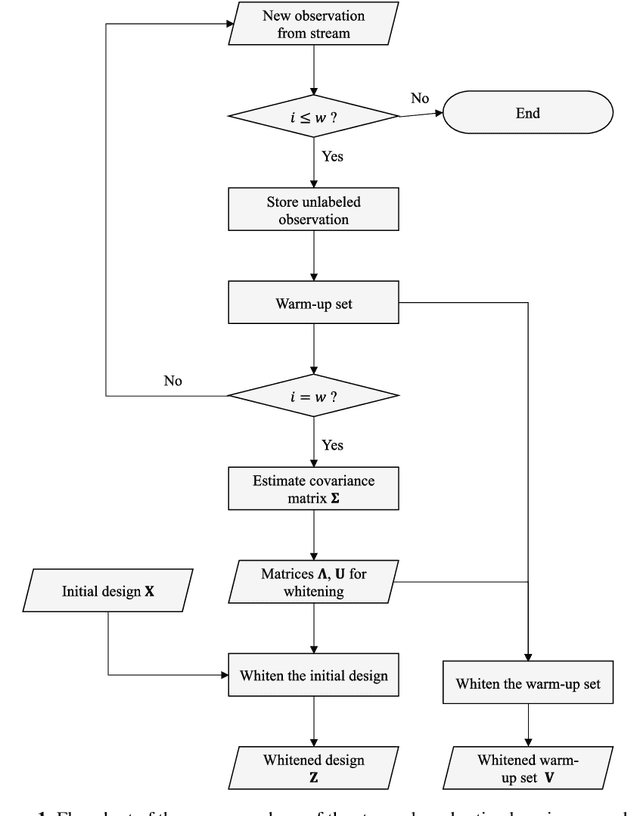

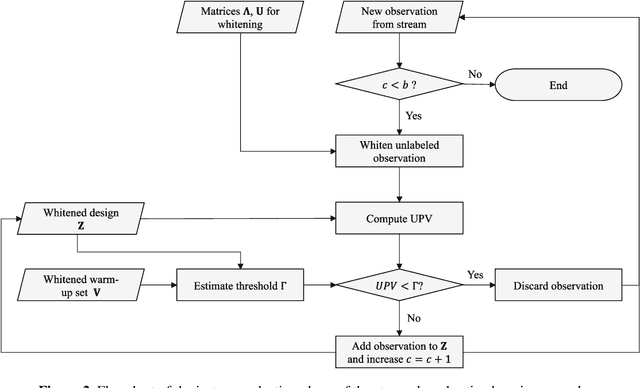
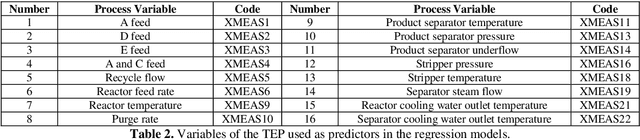
The proliferation of automated data collection schemes and the advances in sensorics are increasing the amount of data we are able to monitor in real-time. However, given the high annotation costs and the time required by quality inspections, data is often available in an unlabeled form. This is fostering the use of active learning for the development of soft sensors and predictive models. In production, instead of performing random inspections to obtain product information, labels are collected by evaluating the information content of the unlabeled data. Several query strategy frameworks for regression have been proposed in the literature but most of the focus has been dedicated to the static pool-based scenario. In this work, we propose a new strategy for the stream-based scenario, where instances are sequentially offered to the learner, which must instantaneously decide whether to perform the quality check to obtain the label or discard the instance. The approach is inspired by the optimal experimental design theory and the iterative aspect of the decision-making process is tackled by setting a threshold on the informativeness of the unlabeled data points. The proposed approach is evaluated using numerical simulations and the Tennessee Eastman Process simulator. The results confirm that selecting the examples suggested by the proposed algorithm allows for a faster reduction in the prediction error.