 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplementing Immune Repertoire Models Using Weighted Finite State Machines
Aug 07, 2023The adaptive immune system's T and B cells can be viewed as large populations of simple, diverse classifiers. Artificial immune systems (AIS) $\unicode{x2013}$ algorithmic models of T or B cell repertoires $\unicode{x2013}$ are used in both computational biology and natural computing to investigate how the immune system adapts to its changing environments. However, researchers have struggled to build such systems at scale. For string-based AISs, finite state machines (FSMs) can store cell repertoires in compressed representations that are orders of magnitude smaller than explicitly stored receptor sets. This strategy allows AISs with billions of receptors to be generated in a matter of seconds. However, to date, these FSM-based AISs have been unable to deal with multiplicity in input data. Here, we show how weighted FSMs can be used to represent cell repertoires and model immunological processes like negative and positive selection, while also taking into account the multiplicity of input data. We use our method to build simple immune-inspired classifier systems that solve various toy problems in anomaly detection, showing how weights can be crucial for both performance and robustness to parameters. Our approach can potentially be extended to increase the scale of other population-based machine learning algorithms such as learning classifier systems.
pgmpy: A Python Toolkit for Bayesian Networks
Apr 17, 2023

Bayesian Networks (BNs) are used in various fields for modeling, prediction, and decision making. pgmpy is a python package that provides a collection of algorithms and tools to work with BNs and related models. It implements algorithms for structure learning, parameter estimation, approximate and exact inference, causal inference, and simulations. These implementations focus on modularity and easy extensibility to allow users to quickly modify/add to existing algorithms, or to implement new algorithms for different use cases. pgmpy is released under the MIT License; the source code is available at: https://github.com/pgmpy/pgmpy, and the documentation at: https://pgmpy.org.
A Simple Unified Approach to Testing High-Dimensional Conditional Independences for Categorical and Ordinal Data
Jun 09, 2022



Conditional independence (CI) tests underlie many approaches to model testing and structure learning in causal inference. Most existing CI tests for categorical and ordinal data stratify the sample by the conditioning variables, perform simple independence tests in each stratum, and combine the results. Unfortunately, the statistical power of this approach degrades rapidly as the number of conditioning variables increases. Here we propose a simple unified CI test for ordinal and categorical data that maintains reasonable calibration and power in high dimensions. We show that our test outperforms existing baselines in model testing and structure learning for dense directed graphical models while being comparable for sparse models. Our approach could be attractive for causal model testing because it is easy to implement, can be used with non-parametric or parametric probability models, has the symmetry property, and has reasonable computational requirements.
Separators and Adjustment Sets in Causal Graphs: Complete Criteria and an Algorithmic Framework
Mar 02, 2018



Principled reasoning about the identifiability of causal effects from non-experimental data is an important application of graphical causal models. We present an algorithmic framework for efficiently testing, constructing, and enumerating $m$-separators in ancestral graphs (AGs), a class of graphical causal models that can represent uncertainty about the presence of latent confounders. Furthermore, we prove a reduction from causal effect identification by covariate adjustment to $m$-separation in a subgraph for directed acyclic graphs (DAGs) and maximal ancestral graphs (MAGs). Jointly, these results yield constructive criteria that characterize all adjustment sets as well as all minimal and minimum adjustment sets for identification of a desired causal effect with multivariate exposures and outcomes in the presence of latent confounding. Our results extend several existing solutions for special cases of these problems. Our efficient algorithms allowed us to empirically quantify the identifiability gap between covariate adjustment and the do-calculus in random DAGs, covering a wide range of scenarios. Implementations of our algorithms are provided in the R package dagitty.
Drawing and Analyzing Causal DAGs with DAGitty
Aug 19, 2015

DAGitty is a software for drawing and analyzing causal diagrams, also known as directed acyclic graphs (DAGs). Functions include identification of minimal sufficient adjustment sets for estimating causal effects, diagnosis of insufficient or invalid adjustment via the identification of biasing paths, identification of instrumental variables, and derivation of testable implications. DAGitty is provided in the hope that it is useful for researchers and students in Epidemiology, Sociology, Psychology, and other empirical disciplines. The software should run in any web browser that supports modern JavaScript, HTML, and SVG. This is the user manual for DAGitty version 2.3. The manual is updated with every release of a new stable version. DAGitty is available at dagitty.net.
Learning from Pairwise Marginal Independencies
Aug 02, 2015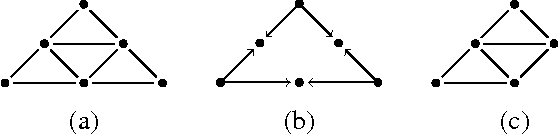


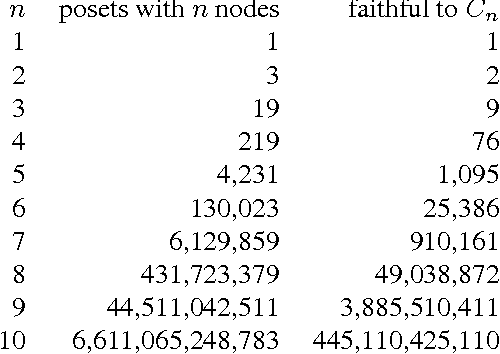
We consider graphs that represent pairwise marginal independencies amongst a set of variables (for instance, the zero entries of a covariance matrix for normal data). We characterize the directed acyclic graphs (DAGs) that faithfully explain a given set of independencies, and derive algorithms to efficiently enumerate such structures. Our results map out the space of faithful causal models for a given set of pairwise marginal independence relations. This allows us to show the extent to which causal inference is possible without using conditional independence tests.
Adjustment Criteria in Causal Diagrams: An Algorithmic Perspective
Feb 14, 2012

Identifying and controlling bias is a key problem in empirical sciences. Causal diagram theory provides graphical criteria for deciding whether and how causal effects can be identified from observed (nonexperimental) data by covariate adjustment. Here we prove equivalences between existing as well as new criteria for adjustment and we provide a new simplified but still equivalent notion of d-separation. These lead to efficient algorithms for two important tasks in causal diagram analysis: (1) listing minimal covariate adjustments (with polynomial delay); and (2) identifying the subdiagram involved in biasing paths (in linear time). Our results improve upon existing exponential-time solutions for these problems, enabling users to assess the effects of covariate adjustment on diagrams with tens to hundreds of variables interactively in real time.