 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConGA: Guidelines for Contextual Gender Annotation. A Framework for Annotating Gender in Machine Translation
Mar 18, 2026Handling gender across languages remains a persistent challenge for Machine Translation (MT) and Large Language Models (LLMs), especially when translating from gender-neutral languages into morphologically gendered ones, such as English to Italian. English largely omits grammatical gender, while Italian requires explicit agreement across multiple grammatical categories. This asymmetry often leads MT systems to default to masculine forms, reinforcing bias and reducing translation accuracy. To address this issue, we present the Contextual Gender Annotation (ConGA) framework, a linguistically grounded set of guidelines for word-level gender annotation. The scheme distinguishes between semantic gender in English through three tags, Masculine (M), Feminine (F), and Ambiguous (A), and grammatical gender realisation in Italian (Masculine (M), Feminine (F)), combined with entity-level identifiers for cross-sentence tracking. We apply ConGA to the gENder-IT dataset, creating a gold-standard resource for evaluating gender bias in translation. Our results reveal systematic masculine overuse and inconsistent feminine realisation, highlighting persistent limitations of current MT systems. By combining fine-grained linguistic annotation with quantitative evaluation, this work offers both a methodology and a benchmark for building more gender-aware and multilingual NLP systems.
A Parallel Cross-Lingual Benchmark for Multimodal Idiomaticity Understanding
Jan 13, 2026Potentially idiomatic expressions (PIEs) construe meanings inherently tied to the everyday experience of a given language community. As such, they constitute an interesting challenge for assessing the linguistic (and to some extent cultural) capabilities of NLP systems. In this paper, we present XMPIE, a parallel multilingual and multimodal dataset of potentially idiomatic expressions. The dataset, containing 34 languages and over ten thousand items, allows comparative analyses of idiomatic patterns among language-specific realisations and preferences in order to gather insights about shared cultural aspects. This parallel dataset allows to evaluate model performance for a given PIE in different languages and whether idiomatic understanding in one language can be transferred to another. Moreover, the dataset supports the study of PIEs across textual and visual modalities, to measure to what extent PIE understanding in one modality transfers or implies in understanding in another modality (text vs. image). The data was created by language experts, with both textual and visual components crafted under multilingual guidelines, and each PIE is accompanied by five images representing a spectrum from idiomatic to literal meanings, including semantically related and random distractors. The result is a high-quality benchmark for evaluating multilingual and multimodal idiomatic language understanding.
GENder-IT: An Annotated English-Italian Parallel Challenge Set for Cross-Linguistic Natural Gender Phenomena
Aug 31, 2021Languages differ in terms of the absence or presence of gender features, the number of gender classes and whether and where gender features are explicitly marked. These cross-linguistic differences can lead to ambiguities that are difficult to resolve, especially for sentence-level MT systems. The identification of ambiguity and its subsequent resolution is a challenging task for which currently there aren't any specific resources or challenge sets available. In this paper, we introduce gENder-IT, an English--Italian challenge set focusing on the resolution of natural gender phenomena by providing word-level gender tags on the English source side and multiple gender alternative translations, where needed, on the Italian target side.
#LaCulturaNonsiFerma: Report on Use and Diffusion of #Hashtags from the Italian Cultural Institutions during the COVID-19 outbreak
Mar 22, 2021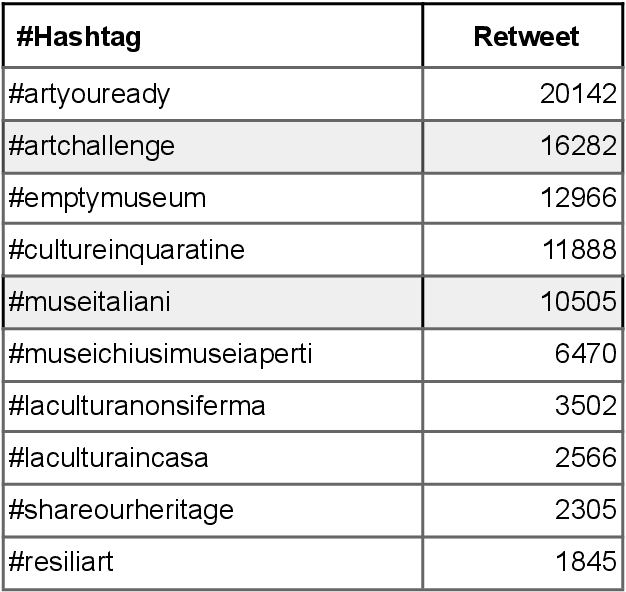
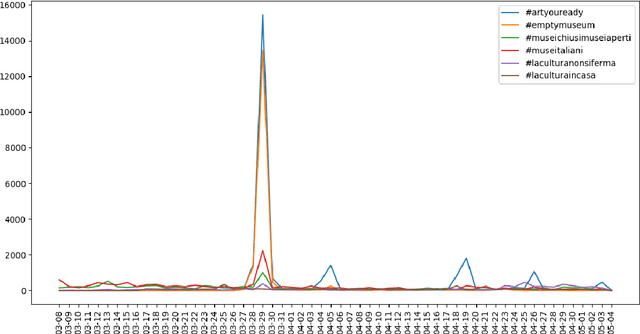
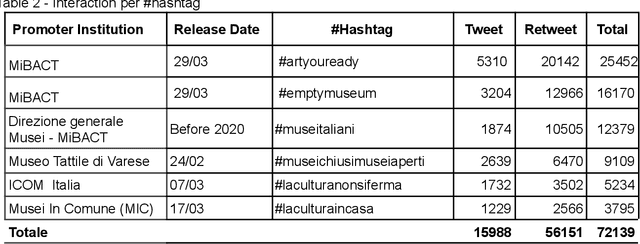
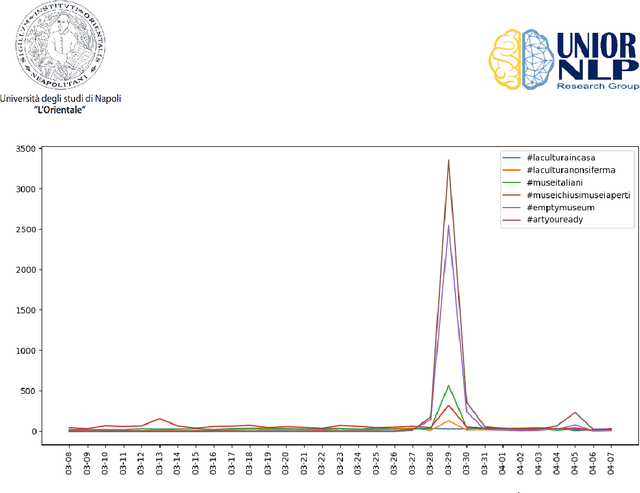
This report presents an analysis of #hashtags used by Italian Cultural Heritage institutions to promote and communicate cultural content during the COVID-19 lock-down period in Italy. Several activities to support and engage users' have been proposed using social media. Most of these activities present one or more #hashtags which help to aggregate content and create a community on specific topics. Results show that on one side Italian institutions have been very proactive in adapting to the pandemic scenario and on the other side users' reacted very positively increasing their participation in the proposed activities.
Gamified Crowdsourcing for Idiom Corpora Construction
Feb 01, 2021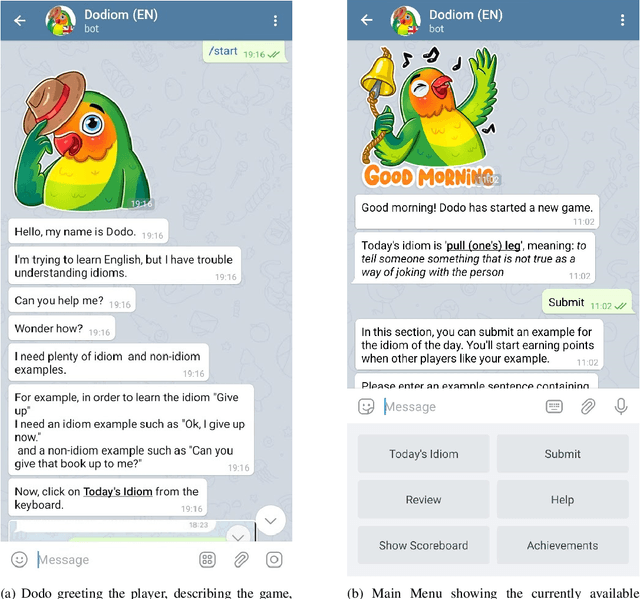

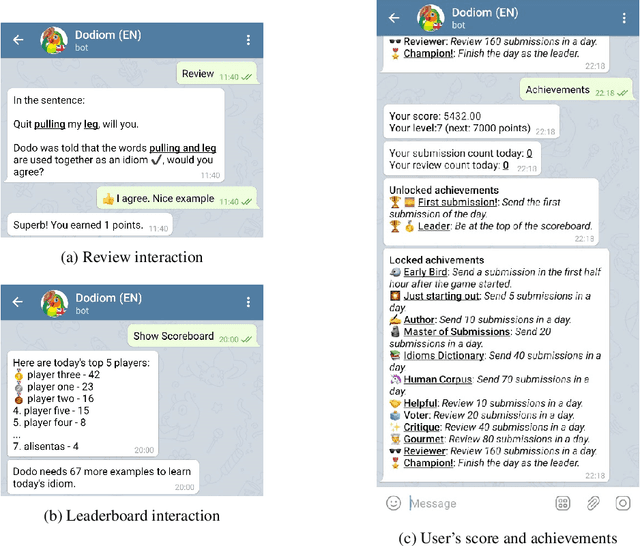
Learning idiomatic expressions is seen as one of the most challenging stages in second language learning because of their unpredictable meaning. A similar situation holds for their identification within natural language processing applications such as machine translation and parsing. The lack of high-quality usage samples exacerbates this challenge not only for humans but also for artificial intelligence systems. This article introduces a gamified crowdsourcing approach for collecting language learning materials for idiomatic expressions; a messaging bot is designed as an asynchronous multiplayer game for native speakers who compete with each other while providing idiomatic and nonidiomatic usage examples and rating other players' entries. As opposed to classical crowdprocessing annotation efforts in the field, for the first time in the literature, a crowdcreating & crowdrating approach is implemented and tested for idiom corpora construction. The approach is language independent and evaluated on two languages in comparison to traditional data preparation techniques in the field. The reaction of the crowd is monitored under different motivational means (namely, gamification affordances and monetary rewards). The results reveal that the proposed approach is powerful in collecting the targeted materials, and although being an explicit crowdsourcing approach, it is found entertaining and useful by the crowd. The approach has been shown to have the potential to speed up the construction of idiom corpora for different natural languages to be used as second language learning material, training data for supervised idiom identification systems, or samples for lexicographic studies.
LaCulturaNonSiFerma -- Report su uso e la diffusione degli hashtag delle istituzioni culturali italiane durante il periodo di lockdown
May 21, 2020This report presents an analysis of #hashtags used by Italian Cultural Heritage institutions to promote and communicate cultural content during the COVID-19 lock-down period in Italy. Several activities to support and engage users' have been proposed using social media. Most of these activities present one or more #hashtags which help to aggregate content and create a community on specific topics. Results show that on one side Italian institutions have been very proactive in adapting to the pandemic scenario and on the other side users' reacted very positively increasing their participation in the proposed activities.